结合过采样技术的双向LSTM网络软件缺陷预测
IF 3.6
3区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
Cluster Computing-The Journal of Networks Software Tools and Applications
Pub Date : 2023-10-28
DOI:10.1007/s10586-023-04170-z
引用次数: 0
摘要
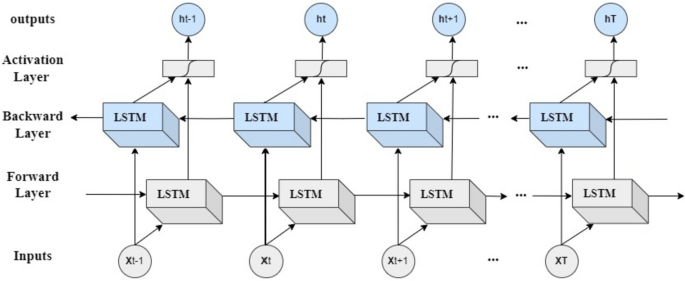
软件缺陷是软件开发中的一个关键问题,它可能导致系统故障并造成重大的经济损失。预测软件缺陷是保证软件质量的一个重要方面。这对节省时间和降低软件测试的总体成本都有很大的影响。在软件缺陷预测(SDP)过程中,自动化工具尝试基于软件度量来预测源代码中的缺陷。已经提出了几个SDP模型来在缺陷发生之前识别和预防缺陷。近年来,递归神经网络(RNN)技术因其处理序列数据和学习复杂模式的能力而受到关注。然而,由于数据不平衡的问题,这些技术并不总是适合于预测软件缺陷。为了解决这一问题,本研究旨在将双向长短期记忆(Bi-LSTM)网络与过采样技术相结合。为了验证所提模型的有效性和效率,在PROMISE存储库中获得的基准数据集上进行了实验。从正确率、精密度、召回率、f-measure、马修相关系数(MCC)、ROC曲线下面积(AUC)、精密度-召回率曲线下面积(AUCPR)和均方误差(MSE)等方面对实验结果进行了比较和评价。该模型在原始数据集和平衡数据集(使用随机过采样和SMOTE)上的平均准确率分别为88%、94%和92%。结果表明,在平衡数据集(使用随机过采样和SMOTE)上提出的Bi-LSTM比原始数据集的平均准确率提高了6%和4%。该模型在原始数据集和平衡数据集(使用随机过采样和SMOTE)上的平均f值分别为51%、94%和92%。结果表明,在平衡数据集(使用随机过采样和SMOTE)上提出的Bi-LSTM与原始数据集相比,平均F-measure分别提高了43%和41%。实验结果表明,将Bi-LSTM网络与过采样技术相结合,对类分布不平衡的数据集的缺陷预测性能有积极的影响。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Software defect prediction using a bidirectional LSTM network combined with oversampling techniques
Abstract Software defects are a critical issue in software development that can lead to system failures and cause significant financial losses. Predicting software defects is a vital aspect of ensuring software quality. This can significantly impact both saving time and reducing the overall cost of software testing. During the software defect prediction (SDP) process, automated tools attempt to predict defects in the source codes based on software metrics. Several SDP models have been proposed to identify and prevent defects before they occur. In recent years, recurrent neural network (RNN) techniques have gained attention for their ability to handle sequential data and learn complex patterns. Still, these techniques are not always suitable for predicting software defects due to the problem of imbalanced data. To deal with this problem, this study aims to combine a bidirectional long short-term memory (Bi-LSTM) network with oversampling techniques. To establish the effectiveness and efficiency of the proposed model, the experiments have been conducted on benchmark datasets obtained from the PROMISE repository. The experimental results have been compared and evaluated in terms of accuracy, precision, recall, f-measure, Matthew’s correlation coefficient (MCC), the area under the ROC curve (AUC), the area under the precision-recall curve (AUCPR) and mean square error (MSE). The average accuracy of the proposed model on the original and balanced datasets (using random oversampling and SMOTE) was 88%, 94%, And 92%, respectively. The results showed that the proposed Bi-LSTM on the balanced datasets (using random oversampling and SMOTE) improves the average accuracy by 6 and 4% compared to the original datasets. The average F-measure of the proposed model on the original and balanced datasets (using random oversampling and SMOTE) were 51%, 94%, And 92%, respectively. The results showed that the proposed Bi-LSTM on the balanced datasets (using random oversampling and SMOTE) improves the average F-measure by 43 and 41% compared to the original datasets. The experimental results demonstrated that combining the Bi-LSTM network with oversampling techniques positively affects defect prediction performance in datasets with imbalanced class distributions.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

CiteScore
9.70
自引率
13.60%
发文量
298
审稿时长
3.0 months
期刊介绍:
Cluster Computing addresses the latest results in these fields that support High Performance Distributed Computing (HPDC). In HPDC environments, parallel and/or distributed computing techniques are applied to the solution of computationally intensive applications across networks of computers. The journal represents an important source of information for the growing number of researchers, developers and users of HPDC environments.
Cluster Computing: the Journal of Networks, Software Tools and Applications provides a forum for presenting the latest research and technology in the fields of parallel processing, distributed computing systems and computer networks.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


