Lingbing Meng, Mengya Yuan, Xuehan Shi, Le Zhang, Qingqing Liu, Dai Ping, Jinhua Wu, Fei Cheng
{"title":"通过跨模态注意力和边界特征引导进行 RGB 深度突出物体检测","authors":"Lingbing Meng, Mengya Yuan, Xuehan Shi, Le Zhang, Qingqing Liu, Dai Ping, Jinhua Wu, Fei Cheng","doi":"10.1049/cvi2.12244","DOIUrl":null,"url":null,"abstract":"<p>RGB depth (RGB-D) salient object detection (SOD) is a meaningful and challenging task, which has achieved good detection performance in dealing with simple scenes using convolutional neural networks, however, it cannot effectively handle scenes with complex contours of salient objects or similarly coloured salient objects and background. A novel end-to-end framework is proposed for RGB-D SOD, which comprises of four main components: the cross-modal attention feature enhancement (CMAFE) module, the multi-level contextual feature interaction (MLCFI) module, the boundary feature extraction (BFE) module, and the multi-level boundary attention guidance (MLBAG) module. The CMAFE module retains the more effective salient features by employing a dual-attention mechanism to filter noise from two modalities. In the MLCFI module, a shuffle operation is used for high-level and low-level channels to promote cross-channel information communication, and rich semantic information is extracted. The BFE module converts salient features into boundary features to generate boundary maps. The MLBAG module produces saliency maps by aggregating multi-level boundary saliency maps to guide cross-modal features in the decode stage. Extensive experiments are conducted on six public benchmark datasets, with the results demonstrating that the proposed model significantly outperforms 23 state-of-the-art RGB-D SOD models with regards to multiple evaluation metrics.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"18 2","pages":"273-288"},"PeriodicalIF":1.5000,"publicationDate":"2023-10-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12244","citationCount":"0","resultStr":"{\"title\":\"RGB depth salient object detection via cross-modal attention and boundary feature guidance\",\"authors\":\"Lingbing Meng, Mengya Yuan, Xuehan Shi, Le Zhang, Qingqing Liu, Dai Ping, Jinhua Wu, Fei Cheng\",\"doi\":\"10.1049/cvi2.12244\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>RGB depth (RGB-D) salient object detection (SOD) is a meaningful and challenging task, which has achieved good detection performance in dealing with simple scenes using convolutional neural networks, however, it cannot effectively handle scenes with complex contours of salient objects or similarly coloured salient objects and background. A novel end-to-end framework is proposed for RGB-D SOD, which comprises of four main components: the cross-modal attention feature enhancement (CMAFE) module, the multi-level contextual feature interaction (MLCFI) module, the boundary feature extraction (BFE) module, and the multi-level boundary attention guidance (MLBAG) module. The CMAFE module retains the more effective salient features by employing a dual-attention mechanism to filter noise from two modalities. In the MLCFI module, a shuffle operation is used for high-level and low-level channels to promote cross-channel information communication, and rich semantic information is extracted. The BFE module converts salient features into boundary features to generate boundary maps. The MLBAG module produces saliency maps by aggregating multi-level boundary saliency maps to guide cross-modal features in the decode stage. Extensive experiments are conducted on six public benchmark datasets, with the results demonstrating that the proposed model significantly outperforms 23 state-of-the-art RGB-D SOD models with regards to multiple evaluation metrics.</p>\",\"PeriodicalId\":56304,\"journal\":{\"name\":\"IET Computer Vision\",\"volume\":\"18 2\",\"pages\":\"273-288\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2023-10-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12244\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12244\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12244","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
RGB depth salient object detection via cross-modal attention and boundary feature guidance
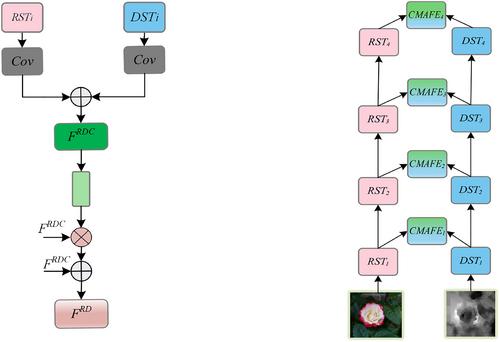
RGB depth (RGB-D) salient object detection (SOD) is a meaningful and challenging task, which has achieved good detection performance in dealing with simple scenes using convolutional neural networks, however, it cannot effectively handle scenes with complex contours of salient objects or similarly coloured salient objects and background. A novel end-to-end framework is proposed for RGB-D SOD, which comprises of four main components: the cross-modal attention feature enhancement (CMAFE) module, the multi-level contextual feature interaction (MLCFI) module, the boundary feature extraction (BFE) module, and the multi-level boundary attention guidance (MLBAG) module. The CMAFE module retains the more effective salient features by employing a dual-attention mechanism to filter noise from two modalities. In the MLCFI module, a shuffle operation is used for high-level and low-level channels to promote cross-channel information communication, and rich semantic information is extracted. The BFE module converts salient features into boundary features to generate boundary maps. The MLBAG module produces saliency maps by aggregating multi-level boundary saliency maps to guide cross-modal features in the decode stage. Extensive experiments are conducted on six public benchmark datasets, with the results demonstrating that the proposed model significantly outperforms 23 state-of-the-art RGB-D SOD models with regards to multiple evaluation metrics.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


