Hao Li, Ju Dai, Rui Zeng, Junxuan Bai, Zhangmeng Chen, Junjun Pan
{"title":"基于关键帧的复杂运动合成的脚约束时空变换器","authors":"Hao Li, Ju Dai, Rui Zeng, Junxuan Bai, Zhangmeng Chen, Junjun Pan","doi":"10.1002/cav.2217","DOIUrl":null,"url":null,"abstract":"<p>Keyframe-based motion synthesis holds significant effects in games and movies. Existing methods for complex motion synthesis often require secondary post-processing to eliminate foot sliding to yield satisfied motions. In this paper, we analyze the cause of the sliding issue attributed to the mismatch between root trajectory and motion postures. To address the problem, we propose a novel end-to-end Spatial-Temporal transformer network conditioned on foot contact information for high-quality keyframe-based motion synthesis. Specifically, our model mainly compromises a spatial-temporal transformer encoder and two decoders to learn motion sequence features and predict motion postures and foot contact states. A novel constrained embedding, which consists of keyframes and foot contact constraints, is incorporated into the model to facilitate network learning from diversified control knowledge. To generate matched root trajectory with motion postures, we design a differentiable root trajectory reconstruction algorithm to construct root trajectory based on the decoder outputs. Qualitative and quantitative experiments on the public LaFAN1, Dance, and Martial Arts datasets demonstrate the superiority of our method in generating high-quality complex motions compared with state-of-the-arts.</p>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"35 1","pages":""},"PeriodicalIF":0.9000,"publicationDate":"2023-09-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Foot-constrained spatial-temporal transformer for keyframe-based complex motion synthesis\",\"authors\":\"Hao Li, Ju Dai, Rui Zeng, Junxuan Bai, Zhangmeng Chen, Junjun Pan\",\"doi\":\"10.1002/cav.2217\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Keyframe-based motion synthesis holds significant effects in games and movies. Existing methods for complex motion synthesis often require secondary post-processing to eliminate foot sliding to yield satisfied motions. In this paper, we analyze the cause of the sliding issue attributed to the mismatch between root trajectory and motion postures. To address the problem, we propose a novel end-to-end Spatial-Temporal transformer network conditioned on foot contact information for high-quality keyframe-based motion synthesis. Specifically, our model mainly compromises a spatial-temporal transformer encoder and two decoders to learn motion sequence features and predict motion postures and foot contact states. A novel constrained embedding, which consists of keyframes and foot contact constraints, is incorporated into the model to facilitate network learning from diversified control knowledge. To generate matched root trajectory with motion postures, we design a differentiable root trajectory reconstruction algorithm to construct root trajectory based on the decoder outputs. Qualitative and quantitative experiments on the public LaFAN1, Dance, and Martial Arts datasets demonstrate the superiority of our method in generating high-quality complex motions compared with state-of-the-arts.</p>\",\"PeriodicalId\":50645,\"journal\":{\"name\":\"Computer Animation and Virtual Worlds\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":0.9000,\"publicationDate\":\"2023-09-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Animation and Virtual Worlds\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/cav.2217\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.2217","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Foot-constrained spatial-temporal transformer for keyframe-based complex motion synthesis
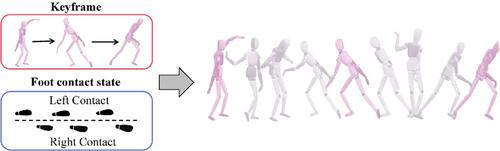
Keyframe-based motion synthesis holds significant effects in games and movies. Existing methods for complex motion synthesis often require secondary post-processing to eliminate foot sliding to yield satisfied motions. In this paper, we analyze the cause of the sliding issue attributed to the mismatch between root trajectory and motion postures. To address the problem, we propose a novel end-to-end Spatial-Temporal transformer network conditioned on foot contact information for high-quality keyframe-based motion synthesis. Specifically, our model mainly compromises a spatial-temporal transformer encoder and two decoders to learn motion sequence features and predict motion postures and foot contact states. A novel constrained embedding, which consists of keyframes and foot contact constraints, is incorporated into the model to facilitate network learning from diversified control knowledge. To generate matched root trajectory with motion postures, we design a differentiable root trajectory reconstruction algorithm to construct root trajectory based on the decoder outputs. Qualitative and quantitative experiments on the public LaFAN1, Dance, and Martial Arts datasets demonstrate the superiority of our method in generating high-quality complex motions compared with state-of-the-arts.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


