多变量时间序列分类中变压器位置编码的改进
IF 4.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 1
摘要
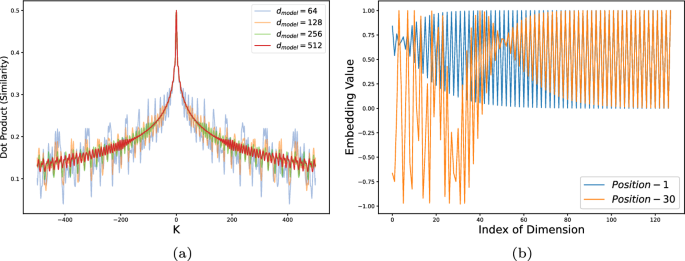
变压器在深度学习的许多应用中表现出了出色的性能。当应用于时间序列数据时,变压器需要有效的位置编码来捕获时间序列数据的顺序。位置编码在时间序列分析中的有效性研究并不充分,存在争议,例如,是注入绝对位置编码还是相对位置编码更好,还是两者结合更好。为了澄清这一点,我们首先回顾了现有的绝对位置和相对位置编码方法在时间序列分类中的应用。然后,我们提出了一种新的用于时间序列数据的绝对位置编码方法,称为时间绝对位置编码(tAPE)。该方法在绝对位置编码中结合了序列长度和输入嵌入维数。此外,我们提出了相对位置编码(eRPE)的计算效率实现,以提高时间序列的通用性。然后,我们提出了一种新的多变量时间序列分类模型,将tAPE/eRPE和基于卷积的输入编码相结合,称为ConvTran,以改善时间序列数据的位置和数据嵌入。所提出的绝对位置和相对位置编码方法简单有效。它们可以很容易地集成到变压器块中,并用于下游任务,如预测、外部回归和异常检测。在32个多变量时间序列数据集上进行的大量实验表明,我们的模型比最先进的卷积和基于变压器的模型要准确得多。代码和模型在https://github.com/Navidfoumani/ConvTran上是开源的。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Improving position encoding of transformers for multivariate time series classification
Abstract Transformers have demonstrated outstanding performance in many applications of deep learning. When applied to time series data, transformers require effective position encoding to capture the ordering of the time series data. The efficacy of position encoding in time series analysis is not well-studied and remains controversial, e.g., whether it is better to inject absolute position encoding or relative position encoding, or a combination of them. In order to clarify this, we first review existing absolute and relative position encoding methods when applied in time series classification. We then proposed a new absolute position encoding method dedicated to time series data called time Absolute Position Encoding (tAPE). Our new method incorporates the series length and input embedding dimension in absolute position encoding. Additionally, we propose computationally Efficient implementation of Relative Position Encoding (eRPE) to improve generalisability for time series. We then propose a novel multivariate time series classification model combining tAPE/eRPE and convolution-based input encoding named ConvTran to improve the position and data embedding of time series data. The proposed absolute and relative position encoding methods are simple and efficient. They can be easily integrated into transformer blocks and used for downstream tasks such as forecasting, extrinsic regression, and anomaly detection. Extensive experiments on 32 multivariate time-series datasets show that our model is significantly more accurate than state-of-the-art convolution and transformer-based models. Code and models are open-sourced at https://github.com/Navidfoumani/ConvTran .
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Data Mining and Knowledge Discovery
工程技术-计算机:人工智能
CiteScore
10.40
自引率
4.20%
发文量
68
审稿时长
10 months
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


