内部,基于源外范例的改进领域泛化风格综合
IF 11.6
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
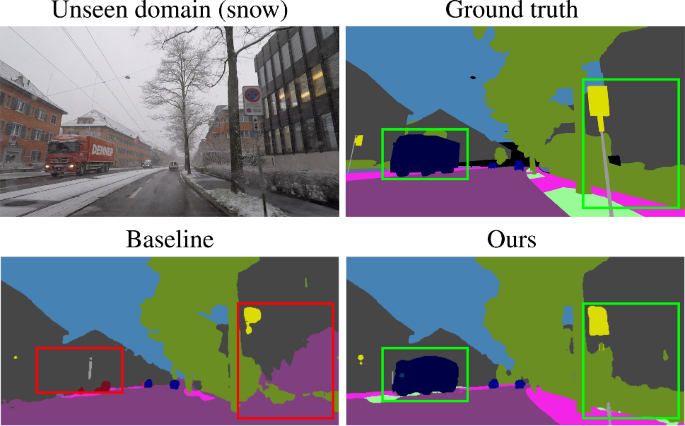
关于领域转移的泛化,因为它们经常出现在自动驾驶等应用中,是深度学习模型面临的最大挑战之一。因此,我们提出了一种基于范例的风格合成管道来提高语义分割中的领域泛化。我们的方法是基于一种新的屏蔽噪声编码器的StyleGAN2反演。该模型学习忠实地重建图像,并通过噪声预测保持图像的语义布局。估计噪声的随机掩蔽使我们的模型具有风格混合能力,即它允许在不影响图像的语义布局的情况下改变全局外观。利用本文提出的掩蔽噪声编码器对训练集中的风格和内容组合进行随机化,即源内风格增强($$\textrm{ISSA}$$ ISSA),有效地增加了训练数据的多样性,降低了伪相关。结果,我们达到了$$12.4\%$$ 12.4 % mIoU improvements on driving-scene semantic segmentation under different types of data shifts, i.e., changing geographic locations, adverse weather conditions, and day to night. $$\textrm{ISSA}$$ ISSA is model-agnostic and straightforwardly applicable with CNNs and Transformers. It is also complementary to other domain generalization techniques, e.g., it improves the recent state-of-the-art solution RobustNet by $$3\%$$ 3 % mIoU in Cityscapes to Dark Zürich. In addition, we demonstrate the strong plug-n-play ability of the proposed style synthesis pipeline, which is readily usable for extra-source exemplars e.g., web-crawled images, without any retraining or fine-tuning. Moreover, we study a new use case to indicate neural network’s generalization capability by building a stylized proxy validation set. This application has significant practical sense for selecting models to be deployed in the open-world environment. Our code is available at https://github.com/boschresearch/ISSA .本文章由计算机程序翻译,如有差异,请以英文原文为准。
Intra- & Extra-Source Exemplar-Based Style Synthesis for Improved Domain Generalization
Abstract The generalization with respect to domain shifts, as they frequently appear in applications such as autonomous driving, is one of the remaining big challenges for deep learning models. Therefore, we propose an exemplar-based style synthesis pipeline to improve domain generalization in semantic segmentation. Our method is based on a novel masked noise encoder for StyleGAN2 inversion. The model learns to faithfully reconstruct the image, preserving its semantic layout through noise prediction. Random masking of the estimated noise enables the style mixing capability of our model, i.e. it allows to alter the global appearance without affecting the semantic layout of an image. Using the proposed masked noise encoder to randomize style and content combinations in the training set, i.e., intra-source style augmentation ( $$\textrm{ISSA}$$ ISSA ) effectively increases the diversity of training data and reduces spurious correlation. As a result, we achieve up to $$12.4\%$$ 12.4 % mIoU improvements on driving-scene semantic segmentation under different types of data shifts, i.e., changing geographic locations, adverse weather conditions, and day to night. $$\textrm{ISSA}$$ ISSA is model-agnostic and straightforwardly applicable with CNNs and Transformers. It is also complementary to other domain generalization techniques, e.g., it improves the recent state-of-the-art solution RobustNet by $$3\%$$ 3 % mIoU in Cityscapes to Dark Zürich. In addition, we demonstrate the strong plug-n-play ability of the proposed style synthesis pipeline, which is readily usable for extra-source exemplars e.g., web-crawled images, without any retraining or fine-tuning. Moreover, we study a new use case to indicate neural network’s generalization capability by building a stylized proxy validation set. This application has significant practical sense for selecting models to be deployed in the open-world environment. Our code is available at https://github.com/boschresearch/ISSA .
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

International Journal of Computer Vision
工程技术-计算机:人工智能
CiteScore
29.80
自引率
2.10%
发文量
163
审稿时长
6 months
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


