好奇的外行人:没有专家标签的细粒度图像识别
IF 11.6
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 5
摘要
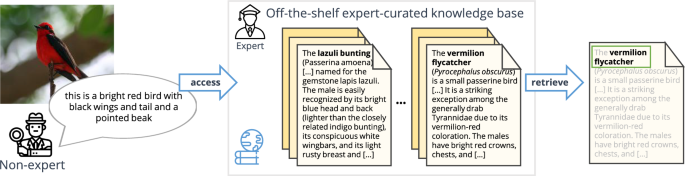
我们大多数人都不是特定领域的专家,比如鸟类学。尽管如此,我们确实有一般的图像和语言理解能力,我们用它来匹配我们所看到的专家资源。这使我们能够在没有外部监督的情况下扩展我们的知识并执行新的任务。相反,机器在咨询专家策划的知识库时要困难得多,除非专门针对这些知识进行培训。因此,在本文中,我们考虑了一个新的问题:没有专家注释的细粒度图像识别,我们通过利用网络百科全书中可用的大量知识来解决这个问题。首先,我们学习了一个模型来描述物体的视觉外观,使用非专家图像描述。然后,我们训练一个细粒度的文本相似度模型,该模型在句子级的基础上将图像描述与文档匹配。我们在两个数据集(CUB-200和Oxford-102 Flowers)上评估了该方法,并与几个强基线和跨模式检索的最新技术进行了比较。代码可从https://github.com/subhc/clever获得。本文章由计算机程序翻译,如有差异,请以英文原文为准。
The Curious Layperson: Fine-Grained Image Recognition Without Expert Labels
Abstract Most of us are not experts in specific fields, such as ornithology. Nonetheless, we do have general image and language understanding capabilities that we use to match what we see to expert resources. This allows us to expand our knowledge and perform novel tasks without ad-hoc external supervision. On the contrary, machines have a much harder time consulting expert-curated knowledge bases unless trained specifically with that knowledge in mind. Thus, in this paper we consider a new problem: fine-grained image recognition without expert annotations, which we address by leveraging the vast knowledge available in web encyclopedias. First, we learn a model to describe the visual appearance of objects using non-expert image descriptions. We then train a fine-grained textual similarity model that matches image descriptions with documents on a sentence-level basis. We evaluate the method on two datasets (CUB-200 and Oxford-102 Flowers) and compare with several strong baselines and the state of the art in cross-modal retrieval. Code is available at: https://github.com/subhc/clever .
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

International Journal of Computer Vision
工程技术-计算机:人工智能
CiteScore
29.80
自引率
2.10%
发文量
163
审稿时长
6 months
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


