{"title":"基于顺序自适应记忆的英北翻译新模型","authors":"Sandeep Saini, Vineet Sahula","doi":"10.1049/ccs2.12011","DOIUrl":null,"url":null,"abstract":"<p>Machine-based language translation has been certainly picking up. Still, machines lag behind the cognitive powers of human beings. Neural Machine Translation (NMT) methods require huge datasets and computational power for high-quality translation. A novel Sequential Adaptive Memory (SAM) cognitive model-based machine translation system for English to Hindi translation, was proposed. This model is an augmented version of the Cortical Learning Algorithm (CLA). The SAM is based on the architecture of the neocortex region of the brain, where speech and language comprehension and production take place. The proposed model is capable of learning with smaller datasets. This model employs the sequence to sequence learning approach, which provides better quality translation. It enables the creation of word pairs, dictionaries, and rules for translation. The results of the proposed approach are compared with the traditional phrase-based SMT approach as well as with the state-of-the-art NMT approach. The results are comparable with the results of the conventional approaches. We illustrate that the limitations of the approaches are won over by the proposed SAM approach. It is observed that SAM is capable of exhibiting satisfactory quality translation for low resource languages as well.</p>","PeriodicalId":33652,"journal":{"name":"Cognitive Computation and Systems","volume":"3 2","pages":"142-153"},"PeriodicalIF":1.3000,"publicationDate":"2021-03-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/ccs2.12011","citationCount":"6","resultStr":"{\"title\":\"A novel model based on Sequential Adaptive Memory for English–Hindi Translation\",\"authors\":\"Sandeep Saini, Vineet Sahula\",\"doi\":\"10.1049/ccs2.12011\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Machine-based language translation has been certainly picking up. Still, machines lag behind the cognitive powers of human beings. Neural Machine Translation (NMT) methods require huge datasets and computational power for high-quality translation. A novel Sequential Adaptive Memory (SAM) cognitive model-based machine translation system for English to Hindi translation, was proposed. This model is an augmented version of the Cortical Learning Algorithm (CLA). The SAM is based on the architecture of the neocortex region of the brain, where speech and language comprehension and production take place. The proposed model is capable of learning with smaller datasets. This model employs the sequence to sequence learning approach, which provides better quality translation. It enables the creation of word pairs, dictionaries, and rules for translation. The results of the proposed approach are compared with the traditional phrase-based SMT approach as well as with the state-of-the-art NMT approach. The results are comparable with the results of the conventional approaches. We illustrate that the limitations of the approaches are won over by the proposed SAM approach. It is observed that SAM is capable of exhibiting satisfactory quality translation for low resource languages as well.</p>\",\"PeriodicalId\":33652,\"journal\":{\"name\":\"Cognitive Computation and Systems\",\"volume\":\"3 2\",\"pages\":\"142-153\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2021-03-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/ccs2.12011\",\"citationCount\":\"6\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Cognitive Computation and Systems\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/ccs2.12011\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation and Systems","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/ccs2.12011","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A novel model based on Sequential Adaptive Memory for English–Hindi Translation
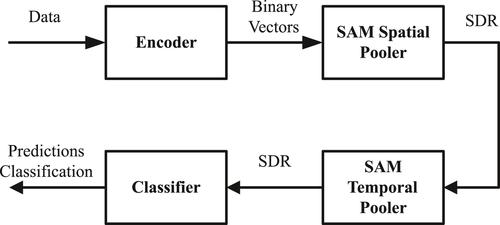
Machine-based language translation has been certainly picking up. Still, machines lag behind the cognitive powers of human beings. Neural Machine Translation (NMT) methods require huge datasets and computational power for high-quality translation. A novel Sequential Adaptive Memory (SAM) cognitive model-based machine translation system for English to Hindi translation, was proposed. This model is an augmented version of the Cortical Learning Algorithm (CLA). The SAM is based on the architecture of the neocortex region of the brain, where speech and language comprehension and production take place. The proposed model is capable of learning with smaller datasets. This model employs the sequence to sequence learning approach, which provides better quality translation. It enables the creation of word pairs, dictionaries, and rules for translation. The results of the proposed approach are compared with the traditional phrase-based SMT approach as well as with the state-of-the-art NMT approach. The results are comparable with the results of the conventional approaches. We illustrate that the limitations of the approaches are won over by the proposed SAM approach. It is observed that SAM is capable of exhibiting satisfactory quality translation for low resource languages as well.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


