Tobias Wegner, Mario Lassnig, Peer Ueberholz, Christian Zeitnitz
{"title":"面向数据密集型科学的云存储缓存仿真与评价。","authors":"Tobias Wegner, Mario Lassnig, Peer Ueberholz, Christian Zeitnitz","doi":"10.1007/s41781-021-00076-w","DOIUrl":null,"url":null,"abstract":"<p><p>A common task in scientific computing is the data reduction. This workflow extracts the most important information from large input data and stores it in smaller derived data objects. The derived data objects can then be used for further analysis. Typically, these workflows use distributed storage and computing resources. A straightforward setup of storage media would be low-cost tape storage and higher-cost disk storage. The large, infrequently accessed input data are stored on tape storage. The smaller, frequently accessed derived data is stored on disk storage. In a best-case scenario, the large input data is only accessed very infrequently and in a well-planned pattern. However, practice shows that often the data has to be processed continuously and unpredictably. This can significantly reduce tape storage performance. A common approach to counter this is storing copies of the large input data on disk storage. This contribution evaluates an approach that uses cloud storage resources to serve as a flexible cache or buffer, depending on the computational workflow. The proposed model is explored for the case of continuously processed data. For the evaluation, a simulation tool was developed, which can be used to analyse models related to storage and network resources. We show that using commercial cloud storage can reduce on-premises disk storage requirements, while maintaining an equal throughput of jobs. Moreover, the key metrics of the model are discussed, and an approach is described, which uses the simulation to assist with the decision process of using commercial cloud storage. The goal is to investigate approaches and propose new evaluation methods to overcome future data challenges.</p>","PeriodicalId":36026,"journal":{"name":"Computing and Software for Big Science","volume":"6 1","pages":"5"},"PeriodicalIF":0.0000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9805534/pdf/","citationCount":"4","resultStr":"{\"title\":\"Simulation and Evaluation of Cloud Storage Caching for Data Intensive Science.\",\"authors\":\"Tobias Wegner, Mario Lassnig, Peer Ueberholz, Christian Zeitnitz\",\"doi\":\"10.1007/s41781-021-00076-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>A common task in scientific computing is the data reduction. This workflow extracts the most important information from large input data and stores it in smaller derived data objects. The derived data objects can then be used for further analysis. Typically, these workflows use distributed storage and computing resources. A straightforward setup of storage media would be low-cost tape storage and higher-cost disk storage. The large, infrequently accessed input data are stored on tape storage. The smaller, frequently accessed derived data is stored on disk storage. In a best-case scenario, the large input data is only accessed very infrequently and in a well-planned pattern. However, practice shows that often the data has to be processed continuously and unpredictably. This can significantly reduce tape storage performance. A common approach to counter this is storing copies of the large input data on disk storage. This contribution evaluates an approach that uses cloud storage resources to serve as a flexible cache or buffer, depending on the computational workflow. The proposed model is explored for the case of continuously processed data. For the evaluation, a simulation tool was developed, which can be used to analyse models related to storage and network resources. We show that using commercial cloud storage can reduce on-premises disk storage requirements, while maintaining an equal throughput of jobs. Moreover, the key metrics of the model are discussed, and an approach is described, which uses the simulation to assist with the decision process of using commercial cloud storage. The goal is to investigate approaches and propose new evaluation methods to overcome future data challenges.</p>\",\"PeriodicalId\":36026,\"journal\":{\"name\":\"Computing and Software for Big Science\",\"volume\":\"6 1\",\"pages\":\"5\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9805534/pdf/\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computing and Software for Big Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s41781-021-00076-w\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computing and Software for Big Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41781-021-00076-w","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
Simulation and Evaluation of Cloud Storage Caching for Data Intensive Science.
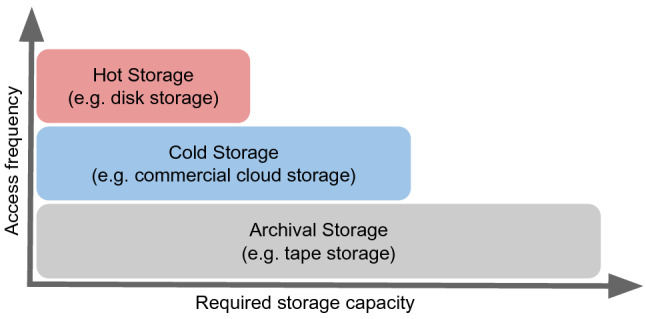
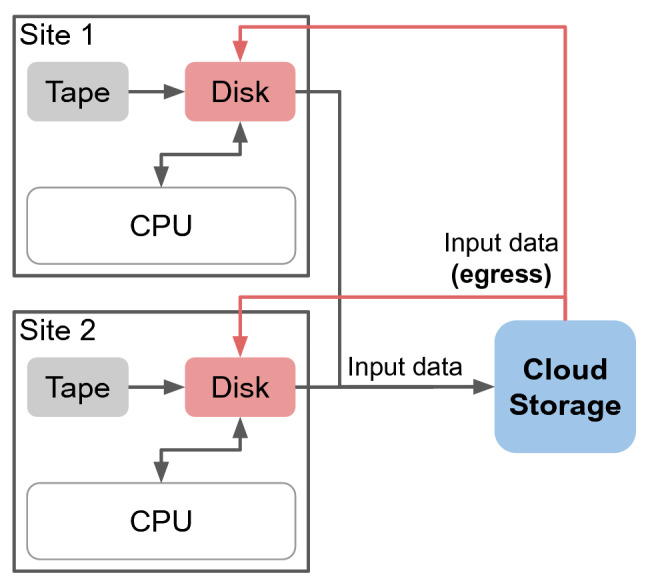
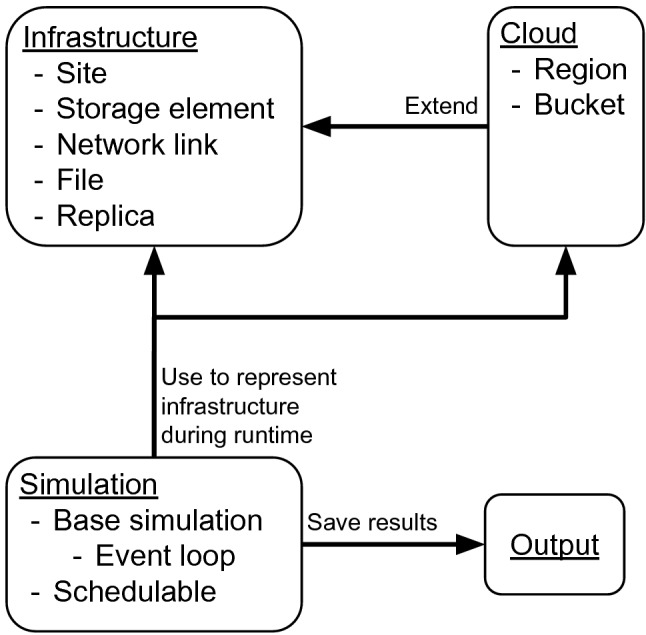
A common task in scientific computing is the data reduction. This workflow extracts the most important information from large input data and stores it in smaller derived data objects. The derived data objects can then be used for further analysis. Typically, these workflows use distributed storage and computing resources. A straightforward setup of storage media would be low-cost tape storage and higher-cost disk storage. The large, infrequently accessed input data are stored on tape storage. The smaller, frequently accessed derived data is stored on disk storage. In a best-case scenario, the large input data is only accessed very infrequently and in a well-planned pattern. However, practice shows that often the data has to be processed continuously and unpredictably. This can significantly reduce tape storage performance. A common approach to counter this is storing copies of the large input data on disk storage. This contribution evaluates an approach that uses cloud storage resources to serve as a flexible cache or buffer, depending on the computational workflow. The proposed model is explored for the case of continuously processed data. For the evaluation, a simulation tool was developed, which can be used to analyse models related to storage and network resources. We show that using commercial cloud storage can reduce on-premises disk storage requirements, while maintaining an equal throughput of jobs. Moreover, the key metrics of the model are discussed, and an approach is described, which uses the simulation to assist with the decision process of using commercial cloud storage. The goal is to investigate approaches and propose new evaluation methods to overcome future data challenges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


