Sean Teebagy, Lauren Colwell, Emma Wood, Antonio Yaghy, Misha Faustina
{"title":"提高ChatGPT-4在OKAP考试中的表现:与ChatGPT-3.5的比较研究。","authors":"Sean Teebagy, Lauren Colwell, Emma Wood, Antonio Yaghy, Misha Faustina","doi":"10.1055/s-0043-1774399","DOIUrl":null,"url":null,"abstract":"<p><p><b>Introduction:</b> This study aims to evaluate the performance of ChatGPT-4, an advanced artificial intelligence (AI) language model, on the Ophthalmology Knowledge Assessment Program (OKAP) examination compared to its predecessor, ChatGPT-3.5. <b>Methods:</b> Both models were tested on 180 OKAP practice questions covering various ophthalmology subject categories. <b>Results:</b> ChatGPT-4 significantly outperformed ChatGPT-3.5 (81% vs. 57%; <i>p</i> <0.001), indicating improvements in medical knowledge assessment. <b>Discussion:</b> The superior performance of ChatGPT-4 suggests potential applicability in ophthalmologic education and clinical decision support systems. Future research should focus on refining AI models, ensuring a balanced representation of fundamental and specialized knowledge, and determining the optimal method of integrating AI into medical education and practice.</p>","PeriodicalId":73579,"journal":{"name":"Journal of academic ophthalmology (2017)","volume":"15 2","pages":"e184-e187"},"PeriodicalIF":0.0000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e6/e4/10-1055-s-0043-1774399.PMC10495224.pdf","citationCount":"2","resultStr":"{\"title\":\"Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5.\",\"authors\":\"Sean Teebagy, Lauren Colwell, Emma Wood, Antonio Yaghy, Misha Faustina\",\"doi\":\"10.1055/s-0043-1774399\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Introduction:</b> This study aims to evaluate the performance of ChatGPT-4, an advanced artificial intelligence (AI) language model, on the Ophthalmology Knowledge Assessment Program (OKAP) examination compared to its predecessor, ChatGPT-3.5. <b>Methods:</b> Both models were tested on 180 OKAP practice questions covering various ophthalmology subject categories. <b>Results:</b> ChatGPT-4 significantly outperformed ChatGPT-3.5 (81% vs. 57%; <i>p</i> <0.001), indicating improvements in medical knowledge assessment. <b>Discussion:</b> The superior performance of ChatGPT-4 suggests potential applicability in ophthalmologic education and clinical decision support systems. Future research should focus on refining AI models, ensuring a balanced representation of fundamental and specialized knowledge, and determining the optimal method of integrating AI into medical education and practice.</p>\",\"PeriodicalId\":73579,\"journal\":{\"name\":\"Journal of academic ophthalmology (2017)\",\"volume\":\"15 2\",\"pages\":\"e184-e187\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e6/e4/10-1055-s-0043-1774399.PMC10495224.pdf\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of academic ophthalmology (2017)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1055/s-0043-1774399\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of academic ophthalmology (2017)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1055/s-0043-1774399","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
摘要
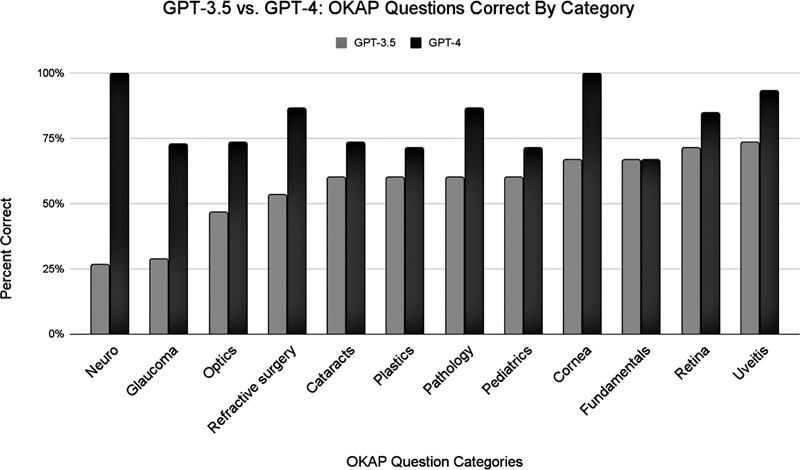
本研究旨在评估先进的人工智能(AI)语言模型ChatGPT-4在眼科知识评估计划(OKAP)考试中的表现,并与其前身ChatGPT-3.5进行比较。方法:采用180道OKAP实践题对两种模型进行检验。结果:ChatGPT-4显著优于ChatGPT-3.5 (81% vs. 57%;p讨论:ChatGPT-4的优越性能表明其在眼科教育和临床决策支持系统中的潜在适用性。未来的研究应侧重于完善人工智能模型,确保基础知识和专业知识的平衡代表,并确定将人工智能融入医学教育和实践的最佳方法。
Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5.
Introduction: This study aims to evaluate the performance of ChatGPT-4, an advanced artificial intelligence (AI) language model, on the Ophthalmology Knowledge Assessment Program (OKAP) examination compared to its predecessor, ChatGPT-3.5. Methods: Both models were tested on 180 OKAP practice questions covering various ophthalmology subject categories. Results: ChatGPT-4 significantly outperformed ChatGPT-3.5 (81% vs. 57%; p <0.001), indicating improvements in medical knowledge assessment. Discussion: The superior performance of ChatGPT-4 suggests potential applicability in ophthalmologic education and clinical decision support systems. Future research should focus on refining AI models, ensuring a balanced representation of fundamental and specialized knowledge, and determining the optimal method of integrating AI into medical education and practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


