Xiaomin Wu, Da-Ting Lin, Rong Chen, Shuvra S Bhattacharyya
{"title":"Jump-GRS:用于神经解码的神经网络结构化剪枝的多阶段方法。","authors":"Xiaomin Wu, Da-Ting Lin, Rong Chen, Shuvra S Bhattacharyya","doi":"10.1088/1741-2552/ace5dc","DOIUrl":null,"url":null,"abstract":"<p><p><i>Objective.</i>Neural decoding, an important area of neural engineering, helps to link neural activity to behavior. Deep neural networks (DNNs), which are becoming increasingly popular in many application fields of machine learning, show promising performance in neural decoding compared to traditional neural decoding methods. Various neural decoding applications, such as brain computer interface applications, require both high decoding accuracy and real-time decoding speed. Pruning methods are used to produce compact DNN models for faster computational speed. Greedy inter-layer order with Random Selection (GRS) is a recently-designed structured pruning method that derives compact DNN models for calcium-imaging-based neural decoding. Although GRS has advantages in terms of detailed structure analysis and consideration of both learned information and model structure during the pruning process, the method is very computationally intensive, and is not feasible when large-scale DNN models need to be pruned within typical constraints on time and computational resources. Large-scale DNN models arise in neural decoding when large numbers of neurons are involved. In this paper, we build on GRS to develop a new structured pruning algorithm called jump GRS (JGRS) that is designed to efficiently compress large-scale DNN models.<i>Approach.</i>On top of GRS, JGRS implements a 'jump mechanism', which bypasses retraining intermediate models when model accuracy is relatively less sensitive to pruning operations. Design of the jump mechanism is motivated by identifying different phases of the structured pruning process, where retraining can be done infrequently in earlier phases without sacrificing accuracy. The jump mechanism helps to significantly speed up execution of the pruning process and greatly enhance its scalability. We compare the pruning performance and speed of JGRS and GRS with extensive experiments in the context of neural decoding.<i>Main results.</i>Our results demonstrate that JGRS provides significantly faster pruning speed compared to GRS, and at the same time, JGRS provides pruned models that are similarly compact as those generated by GRS.<i>Significance.</i>In our experiments, we demonstrate that JGRS achieves on average 9%-20% more compressed models compared to GRS with 2-8 times faster speed (less time required for pruning) across four different initial models on a relevant dataset for neural data analysis.</p>","PeriodicalId":16753,"journal":{"name":"Journal of neural engineering","volume":"20 4","pages":""},"PeriodicalIF":3.8000,"publicationDate":"2023-07-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10801788/pdf/","citationCount":"0","resultStr":"{\"title\":\"Jump-GRS: a multi-phase approach to structured pruning of neural networks for neural decoding.\",\"authors\":\"Xiaomin Wu, Da-Ting Lin, Rong Chen, Shuvra S Bhattacharyya\",\"doi\":\"10.1088/1741-2552/ace5dc\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><i>Objective.</i>Neural decoding, an important area of neural engineering, helps to link neural activity to behavior. Deep neural networks (DNNs), which are becoming increasingly popular in many application fields of machine learning, show promising performance in neural decoding compared to traditional neural decoding methods. Various neural decoding applications, such as brain computer interface applications, require both high decoding accuracy and real-time decoding speed. Pruning methods are used to produce compact DNN models for faster computational speed. Greedy inter-layer order with Random Selection (GRS) is a recently-designed structured pruning method that derives compact DNN models for calcium-imaging-based neural decoding. Although GRS has advantages in terms of detailed structure analysis and consideration of both learned information and model structure during the pruning process, the method is very computationally intensive, and is not feasible when large-scale DNN models need to be pruned within typical constraints on time and computational resources. Large-scale DNN models arise in neural decoding when large numbers of neurons are involved. In this paper, we build on GRS to develop a new structured pruning algorithm called jump GRS (JGRS) that is designed to efficiently compress large-scale DNN models.<i>Approach.</i>On top of GRS, JGRS implements a 'jump mechanism', which bypasses retraining intermediate models when model accuracy is relatively less sensitive to pruning operations. Design of the jump mechanism is motivated by identifying different phases of the structured pruning process, where retraining can be done infrequently in earlier phases without sacrificing accuracy. The jump mechanism helps to significantly speed up execution of the pruning process and greatly enhance its scalability. We compare the pruning performance and speed of JGRS and GRS with extensive experiments in the context of neural decoding.<i>Main results.</i>Our results demonstrate that JGRS provides significantly faster pruning speed compared to GRS, and at the same time, JGRS provides pruned models that are similarly compact as those generated by GRS.<i>Significance.</i>In our experiments, we demonstrate that JGRS achieves on average 9%-20% more compressed models compared to GRS with 2-8 times faster speed (less time required for pruning) across four different initial models on a relevant dataset for neural data analysis.</p>\",\"PeriodicalId\":16753,\"journal\":{\"name\":\"Journal of neural engineering\",\"volume\":\"20 4\",\"pages\":\"\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2023-07-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10801788/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of neural engineering\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1088/1741-2552/ace5dc\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of neural engineering","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1088/1741-2552/ace5dc","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
Jump-GRS: a multi-phase approach to structured pruning of neural networks for neural decoding.
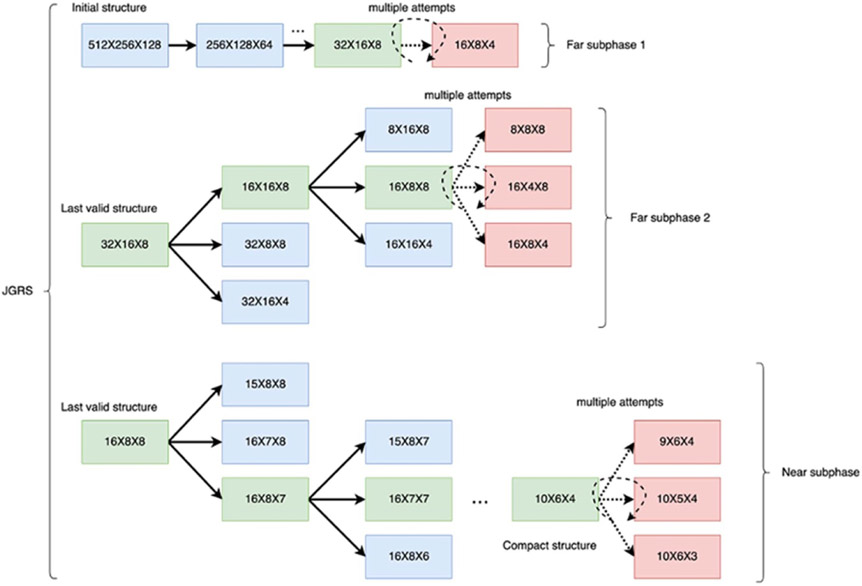
Objective.Neural decoding, an important area of neural engineering, helps to link neural activity to behavior. Deep neural networks (DNNs), which are becoming increasingly popular in many application fields of machine learning, show promising performance in neural decoding compared to traditional neural decoding methods. Various neural decoding applications, such as brain computer interface applications, require both high decoding accuracy and real-time decoding speed. Pruning methods are used to produce compact DNN models for faster computational speed. Greedy inter-layer order with Random Selection (GRS) is a recently-designed structured pruning method that derives compact DNN models for calcium-imaging-based neural decoding. Although GRS has advantages in terms of detailed structure analysis and consideration of both learned information and model structure during the pruning process, the method is very computationally intensive, and is not feasible when large-scale DNN models need to be pruned within typical constraints on time and computational resources. Large-scale DNN models arise in neural decoding when large numbers of neurons are involved. In this paper, we build on GRS to develop a new structured pruning algorithm called jump GRS (JGRS) that is designed to efficiently compress large-scale DNN models.Approach.On top of GRS, JGRS implements a 'jump mechanism', which bypasses retraining intermediate models when model accuracy is relatively less sensitive to pruning operations. Design of the jump mechanism is motivated by identifying different phases of the structured pruning process, where retraining can be done infrequently in earlier phases without sacrificing accuracy. The jump mechanism helps to significantly speed up execution of the pruning process and greatly enhance its scalability. We compare the pruning performance and speed of JGRS and GRS with extensive experiments in the context of neural decoding.Main results.Our results demonstrate that JGRS provides significantly faster pruning speed compared to GRS, and at the same time, JGRS provides pruned models that are similarly compact as those generated by GRS.Significance.In our experiments, we demonstrate that JGRS achieves on average 9%-20% more compressed models compared to GRS with 2-8 times faster speed (less time required for pruning) across four different initial models on a relevant dataset for neural data analysis.
期刊介绍:
The goal of Journal of Neural Engineering (JNE) is to act as a forum for the interdisciplinary field of neural engineering where neuroscientists, neurobiologists and engineers can publish their work in one periodical that bridges the gap between neuroscience and engineering. The journal publishes articles in the field of neural engineering at the molecular, cellular and systems levels.
The scope of the journal encompasses experimental, computational, theoretical, clinical and applied aspects of: Innovative neurotechnology; Brain-machine (computer) interface; Neural interfacing; Bioelectronic medicines; Neuromodulation; Neural prostheses; Neural control; Neuro-rehabilitation; Neurorobotics; Optical neural engineering; Neural circuits: artificial & biological; Neuromorphic engineering; Neural tissue regeneration; Neural signal processing; Theoretical and computational neuroscience; Systems neuroscience; Translational neuroscience; Neuroimaging.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


