Jie Pan, Zilong Zhang, Steven Ray Peters, Shabnam Vatanpour, Robin L Walker, Seungwon Lee, Elliot A Martin, Hude Quan
{"title":"基于自然语言处理的住院电子病历数据中脑血管病病例识别。","authors":"Jie Pan, Zilong Zhang, Steven Ray Peters, Shabnam Vatanpour, Robin L Walker, Seungwon Lee, Elliot A Martin, Hude Quan","doi":"10.1186/s40708-023-00203-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Abstracting cerebrovascular disease (CeVD) from inpatient electronic medical records (EMRs) through natural language processing (NLP) is pivotal for automated disease surveillance and improving patient outcomes. Existing methods rely on coders' abstraction, which has time delays and under-coding issues. This study sought to develop an NLP-based method to detect CeVD using EMR clinical notes.</p><p><strong>Methods: </strong>CeVD status was confirmed through a chart review on randomly selected hospitalized patients who were 18 years or older and discharged from 3 hospitals in Calgary, Alberta, Canada, between January 1 and June 30, 2015. These patients' chart data were linked to administrative discharge abstract database (DAD) and Sunrise<sup>™</sup> Clinical Manager (SCM) EMR database records by Personal Health Number (a unique lifetime identifier) and admission date. We trained multiple natural language processing (NLP) predictive models by combining two clinical concept extraction methods and two supervised machine learning (ML) methods: random forest and XGBoost. Using chart review as the reference standard, we compared the model performances with those of the commonly applied International Classification of Diseases (ICD-10-CA) codes, on the metrics of sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV).</p><p><strong>Result: </strong>Of the study sample (n = 3036), the prevalence of CeVD was 11.8% (n = 360); the median patient age was 63; and females accounted for 50.3% (n = 1528) based on chart data. Among 49 extracted clinical documents from the EMR, four document types were identified as the most influential text sources for identifying CeVD disease (\"nursing transfer report,\" \"discharge summary,\" \"nursing notes,\" and \"inpatient consultation.\"). The best performing NLP model was XGBoost, combining the Unified Medical Language System concepts extracted by cTAKES (e.g., top-ranked concepts, \"Cerebrovascular accident\" and \"Transient ischemic attack\"), and the term frequency-inverse document frequency vectorizer. Compared with ICD codes, the model achieved higher validity overall, such as sensitivity (25.0% vs 70.0%), specificity (99.3% vs 99.1%), PPV (82.6 vs. 87.8%), and NPV (90.8% vs 97.1%).</p><p><strong>Conclusion: </strong>The NLP algorithm developed in this study performed better than the ICD code algorithm in detecting CeVD. The NLP models could result in an automated EMR tool for identifying CeVD cases and be applied for future studies such as surveillance, and longitudinal studies.</p>","PeriodicalId":37465,"journal":{"name":"Brain Informatics","volume":"10 1","pages":"22"},"PeriodicalIF":4.5000,"publicationDate":"2023-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10474977/pdf/","citationCount":"0","resultStr":"{\"title\":\"Cerebrovascular disease case identification in inpatient electronic medical record data using natural language processing.\",\"authors\":\"Jie Pan, Zilong Zhang, Steven Ray Peters, Shabnam Vatanpour, Robin L Walker, Seungwon Lee, Elliot A Martin, Hude Quan\",\"doi\":\"10.1186/s40708-023-00203-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Abstracting cerebrovascular disease (CeVD) from inpatient electronic medical records (EMRs) through natural language processing (NLP) is pivotal for automated disease surveillance and improving patient outcomes. Existing methods rely on coders' abstraction, which has time delays and under-coding issues. This study sought to develop an NLP-based method to detect CeVD using EMR clinical notes.</p><p><strong>Methods: </strong>CeVD status was confirmed through a chart review on randomly selected hospitalized patients who were 18 years or older and discharged from 3 hospitals in Calgary, Alberta, Canada, between January 1 and June 30, 2015. These patients' chart data were linked to administrative discharge abstract database (DAD) and Sunrise<sup>™</sup> Clinical Manager (SCM) EMR database records by Personal Health Number (a unique lifetime identifier) and admission date. We trained multiple natural language processing (NLP) predictive models by combining two clinical concept extraction methods and two supervised machine learning (ML) methods: random forest and XGBoost. Using chart review as the reference standard, we compared the model performances with those of the commonly applied International Classification of Diseases (ICD-10-CA) codes, on the metrics of sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV).</p><p><strong>Result: </strong>Of the study sample (n = 3036), the prevalence of CeVD was 11.8% (n = 360); the median patient age was 63; and females accounted for 50.3% (n = 1528) based on chart data. Among 49 extracted clinical documents from the EMR, four document types were identified as the most influential text sources for identifying CeVD disease (\\\"nursing transfer report,\\\" \\\"discharge summary,\\\" \\\"nursing notes,\\\" and \\\"inpatient consultation.\\\"). The best performing NLP model was XGBoost, combining the Unified Medical Language System concepts extracted by cTAKES (e.g., top-ranked concepts, \\\"Cerebrovascular accident\\\" and \\\"Transient ischemic attack\\\"), and the term frequency-inverse document frequency vectorizer. Compared with ICD codes, the model achieved higher validity overall, such as sensitivity (25.0% vs 70.0%), specificity (99.3% vs 99.1%), PPV (82.6 vs. 87.8%), and NPV (90.8% vs 97.1%).</p><p><strong>Conclusion: </strong>The NLP algorithm developed in this study performed better than the ICD code algorithm in detecting CeVD. The NLP models could result in an automated EMR tool for identifying CeVD cases and be applied for future studies such as surveillance, and longitudinal studies.</p>\",\"PeriodicalId\":37465,\"journal\":{\"name\":\"Brain Informatics\",\"volume\":\"10 1\",\"pages\":\"22\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2023-09-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10474977/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Brain Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s40708-023-00203-w\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Brain Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s40708-023-00203-w","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
Cerebrovascular disease case identification in inpatient electronic medical record data using natural language processing.
Background: Abstracting cerebrovascular disease (CeVD) from inpatient electronic medical records (EMRs) through natural language processing (NLP) is pivotal for automated disease surveillance and improving patient outcomes. Existing methods rely on coders' abstraction, which has time delays and under-coding issues. This study sought to develop an NLP-based method to detect CeVD using EMR clinical notes.
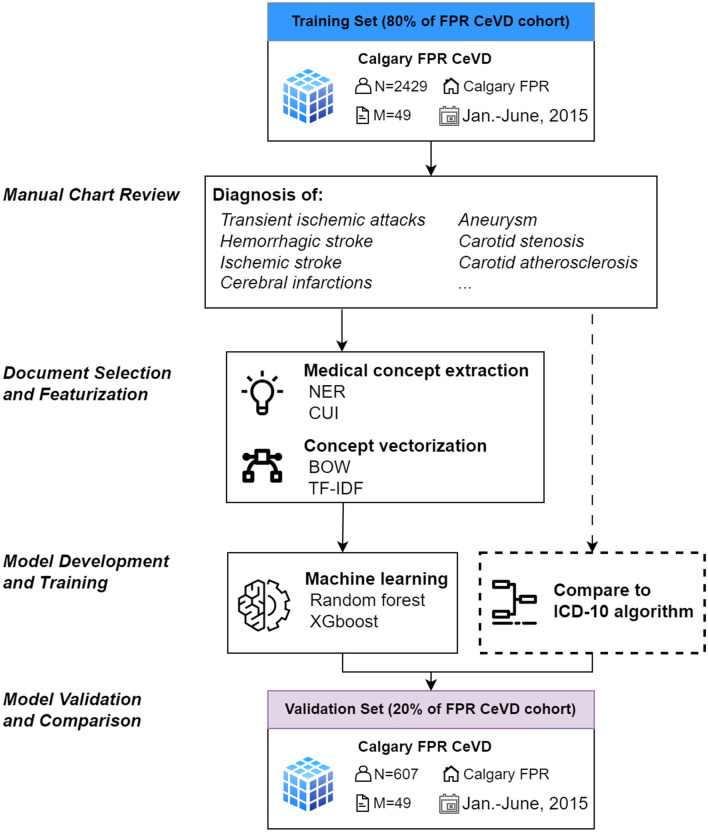
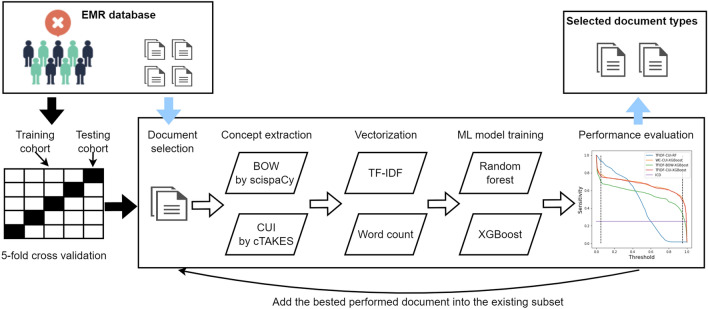
Methods: CeVD status was confirmed through a chart review on randomly selected hospitalized patients who were 18 years or older and discharged from 3 hospitals in Calgary, Alberta, Canada, between January 1 and June 30, 2015. These patients' chart data were linked to administrative discharge abstract database (DAD) and Sunrise™ Clinical Manager (SCM) EMR database records by Personal Health Number (a unique lifetime identifier) and admission date. We trained multiple natural language processing (NLP) predictive models by combining two clinical concept extraction methods and two supervised machine learning (ML) methods: random forest and XGBoost. Using chart review as the reference standard, we compared the model performances with those of the commonly applied International Classification of Diseases (ICD-10-CA) codes, on the metrics of sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV).
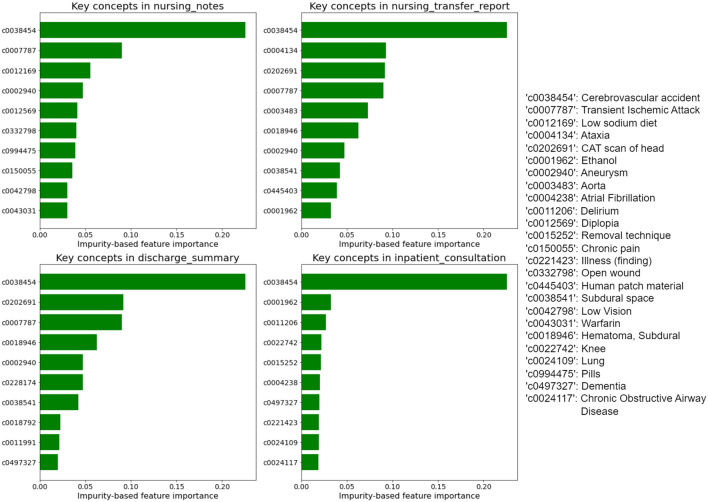
Result: Of the study sample (n = 3036), the prevalence of CeVD was 11.8% (n = 360); the median patient age was 63; and females accounted for 50.3% (n = 1528) based on chart data. Among 49 extracted clinical documents from the EMR, four document types were identified as the most influential text sources for identifying CeVD disease ("nursing transfer report," "discharge summary," "nursing notes," and "inpatient consultation."). The best performing NLP model was XGBoost, combining the Unified Medical Language System concepts extracted by cTAKES (e.g., top-ranked concepts, "Cerebrovascular accident" and "Transient ischemic attack"), and the term frequency-inverse document frequency vectorizer. Compared with ICD codes, the model achieved higher validity overall, such as sensitivity (25.0% vs 70.0%), specificity (99.3% vs 99.1%), PPV (82.6 vs. 87.8%), and NPV (90.8% vs 97.1%).
Conclusion: The NLP algorithm developed in this study performed better than the ICD code algorithm in detecting CeVD. The NLP models could result in an automated EMR tool for identifying CeVD cases and be applied for future studies such as surveillance, and longitudinal studies.
期刊介绍:
Brain Informatics is an international, peer-reviewed, interdisciplinary open-access journal published under the brand SpringerOpen, which provides a unique platform for researchers and practitioners to disseminate original research on computational and informatics technologies related to brain. This journal addresses the computational, cognitive, physiological, biological, physical, ecological and social perspectives of brain informatics. It also welcomes emerging information technologies and advanced neuro-imaging technologies, such as big data analytics and interactive knowledge discovery related to various large-scale brain studies and their applications. This journal will publish high-quality original research papers, brief reports and critical reviews in all theoretical, technological, clinical and interdisciplinary studies that make up the field of brain informatics and its applications in brain-machine intelligence, brain-inspired intelligent systems, mental health and brain disorders, etc. The scope of papers includes the following five tracks: Track 1: Cognitive and Computational Foundations of Brain Science Track 2: Human Information Processing Systems Track 3: Brain Big Data Analytics, Curation and Management Track 4: Informatics Paradigms for Brain and Mental Health Research Track 5: Brain-Machine Intelligence and Brain-Inspired Computing

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


