{"title":"使用深度学习揭穿多语言社交媒体帖子。","authors":"Bina Kotiyal, Heman Pathak, Nipur Singh","doi":"10.1007/s41870-023-01288-6","DOIUrl":null,"url":null,"abstract":"<p><p>Fake news on social media has become a growing concern due to its potential impact on shaping public opinion. The proposed Debunking Multi-Lingual Social Media Posts using Deep Learning (DSMPD) approach offers a promising solution to detect fake news. The DSMPD approach involves creating a dataset of English and Hindi social media posts using web scraping and Natural Language Processing (NLP) techniques. This dataset is then used to train, test, and validate a deep learning-based model that extracts various features, including Embedding from Language Models (ELMo), word and n-gram counts, Term Frequency-Inverse Document Frequency (TF-IDF), sentiments, polarity, and Named Entity Recognition (NER). Based on these features, the model classifies news items into five categories: real, could be real, could be fabricated, fabricated, or dangerously fabricated. To evaluate the performance of the classifiers, the researchers used two datasets comprising over 45,000 articles. Machine learning (ML) algorithms and Deep learning (DL) model are compared to choose the best option for classification and prediction.</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":" ","pages":"1-13"},"PeriodicalIF":0.0000,"publicationDate":"2023-06-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10239612/pdf/","citationCount":"4","resultStr":"{\"title\":\"Debunking multi-lingual social media posts using deep learning.\",\"authors\":\"Bina Kotiyal, Heman Pathak, Nipur Singh\",\"doi\":\"10.1007/s41870-023-01288-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Fake news on social media has become a growing concern due to its potential impact on shaping public opinion. The proposed Debunking Multi-Lingual Social Media Posts using Deep Learning (DSMPD) approach offers a promising solution to detect fake news. The DSMPD approach involves creating a dataset of English and Hindi social media posts using web scraping and Natural Language Processing (NLP) techniques. This dataset is then used to train, test, and validate a deep learning-based model that extracts various features, including Embedding from Language Models (ELMo), word and n-gram counts, Term Frequency-Inverse Document Frequency (TF-IDF), sentiments, polarity, and Named Entity Recognition (NER). Based on these features, the model classifies news items into five categories: real, could be real, could be fabricated, fabricated, or dangerously fabricated. To evaluate the performance of the classifiers, the researchers used two datasets comprising over 45,000 articles. Machine learning (ML) algorithms and Deep learning (DL) model are compared to choose the best option for classification and prediction.</p>\",\"PeriodicalId\":73455,\"journal\":{\"name\":\"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management\",\"volume\":\" \",\"pages\":\"1-13\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-06-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10239612/pdf/\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s41870-023-01288-6\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-023-01288-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Debunking multi-lingual social media posts using deep learning.
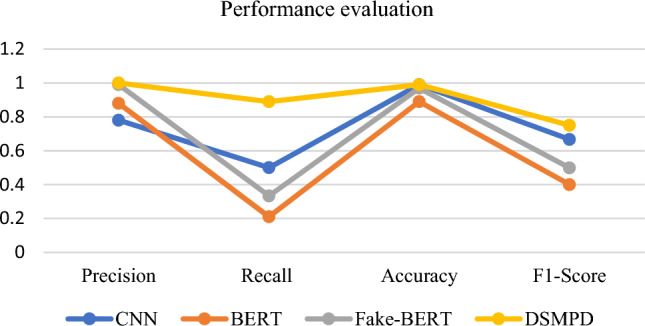
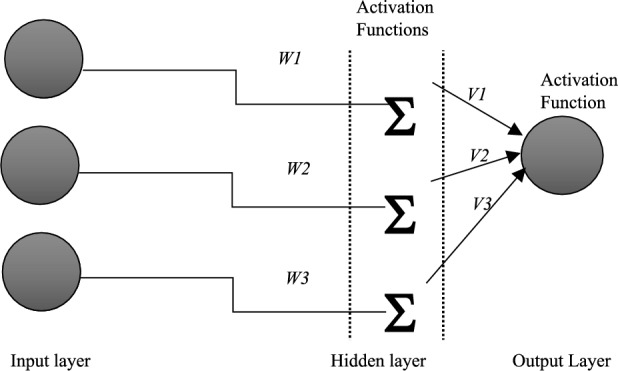
Fake news on social media has become a growing concern due to its potential impact on shaping public opinion. The proposed Debunking Multi-Lingual Social Media Posts using Deep Learning (DSMPD) approach offers a promising solution to detect fake news. The DSMPD approach involves creating a dataset of English and Hindi social media posts using web scraping and Natural Language Processing (NLP) techniques. This dataset is then used to train, test, and validate a deep learning-based model that extracts various features, including Embedding from Language Models (ELMo), word and n-gram counts, Term Frequency-Inverse Document Frequency (TF-IDF), sentiments, polarity, and Named Entity Recognition (NER). Based on these features, the model classifies news items into five categories: real, could be real, could be fabricated, fabricated, or dangerously fabricated. To evaluate the performance of the classifiers, the researchers used two datasets comprising over 45,000 articles. Machine learning (ML) algorithms and Deep learning (DL) model are compared to choose the best option for classification and prediction.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


