Eka Miranda, Suko Adiarto, Faqir M Bhatti, Alfi Yusrotis Zakiyyah, Mediana Aryuni, Charles Bernando
{"title":"使用电子健康记录了解动脉硬化性心脏病患者:机器学习和Shapley加性解释方法。","authors":"Eka Miranda, Suko Adiarto, Faqir M Bhatti, Alfi Yusrotis Zakiyyah, Mediana Aryuni, Charles Bernando","doi":"10.4258/hir.2023.29.3.228","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The number of deaths from cardiovascular disease is projected to reach 23.3 million by 2030. As a contribution to preventing this phenomenon, this paper proposed a machine learning (ML) model to predict patients with arteriosclerotic heart disease (AHD). We also interpreted the prediction model results based on the ML approach and deployed modelagnostic ML methods to identify informative features and their interpretations.</p><p><strong>Methods: </strong>We used a hematology Electronic Health Record (EHR) with information on erythrocytes, hematocrit, hemoglobin, mean corpuscular hemoglobin, mean corpuscular hemoglobin concentration, leukocytes, thrombocytes, age, and sex. To detect and predict AHD, we explored random forest (RF), XGBoost, and AdaBoost models. We examined the prediction model results based on the confusion matrix and accuracy measures. We used the Shapley Additive exPlanations (SHAP) framework to interpret the ML model and quantify the contribution of features to predictions.</p><p><strong>Results: </strong>Our study included data from 6,837 patients, with 4,702 records from patients diagnosed with AHD and 2,135 records from patients without an AHD diagnosis. AdaBoost outperformed RF and XGBoost, achieving an accuracy of 0.78, precision of 0.82, F1-score of 0.85, and recall of 0.88. According to the SHAP summary bar plot method, hemoglobin was the most important attribute for detecting and predicting AHD patients. The SHAP local interpretability bar plot revealed that hemoglobin and mean corpuscular hemoglobin concentration had positive impacts on AHD prediction based on a single observation.</p><p><strong>Conclusions: </strong>ML models based on real clinical data can be used to predict AHD.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":"29 3","pages":"228-238"},"PeriodicalIF":2.1000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e7/3a/hir-2023-29-3-228.PMC10440196.pdf","citationCount":"1","resultStr":"{\"title\":\"Understanding Arteriosclerotic Heart Disease Patients Using Electronic Health Records: A Machine Learning and Shapley Additive exPlanations Approach.\",\"authors\":\"Eka Miranda, Suko Adiarto, Faqir M Bhatti, Alfi Yusrotis Zakiyyah, Mediana Aryuni, Charles Bernando\",\"doi\":\"10.4258/hir.2023.29.3.228\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>The number of deaths from cardiovascular disease is projected to reach 23.3 million by 2030. As a contribution to preventing this phenomenon, this paper proposed a machine learning (ML) model to predict patients with arteriosclerotic heart disease (AHD). We also interpreted the prediction model results based on the ML approach and deployed modelagnostic ML methods to identify informative features and their interpretations.</p><p><strong>Methods: </strong>We used a hematology Electronic Health Record (EHR) with information on erythrocytes, hematocrit, hemoglobin, mean corpuscular hemoglobin, mean corpuscular hemoglobin concentration, leukocytes, thrombocytes, age, and sex. To detect and predict AHD, we explored random forest (RF), XGBoost, and AdaBoost models. We examined the prediction model results based on the confusion matrix and accuracy measures. We used the Shapley Additive exPlanations (SHAP) framework to interpret the ML model and quantify the contribution of features to predictions.</p><p><strong>Results: </strong>Our study included data from 6,837 patients, with 4,702 records from patients diagnosed with AHD and 2,135 records from patients without an AHD diagnosis. AdaBoost outperformed RF and XGBoost, achieving an accuracy of 0.78, precision of 0.82, F1-score of 0.85, and recall of 0.88. According to the SHAP summary bar plot method, hemoglobin was the most important attribute for detecting and predicting AHD patients. The SHAP local interpretability bar plot revealed that hemoglobin and mean corpuscular hemoglobin concentration had positive impacts on AHD prediction based on a single observation.</p><p><strong>Conclusions: </strong>ML models based on real clinical data can be used to predict AHD.</p>\",\"PeriodicalId\":12947,\"journal\":{\"name\":\"Healthcare Informatics Research\",\"volume\":\"29 3\",\"pages\":\"228-238\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e7/3a/hir-2023-29-3-228.PMC10440196.pdf\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Healthcare Informatics Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4258/hir.2023.29.3.228\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2023.29.3.228","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Understanding Arteriosclerotic Heart Disease Patients Using Electronic Health Records: A Machine Learning and Shapley Additive exPlanations Approach.
Objectives: The number of deaths from cardiovascular disease is projected to reach 23.3 million by 2030. As a contribution to preventing this phenomenon, this paper proposed a machine learning (ML) model to predict patients with arteriosclerotic heart disease (AHD). We also interpreted the prediction model results based on the ML approach and deployed modelagnostic ML methods to identify informative features and their interpretations.
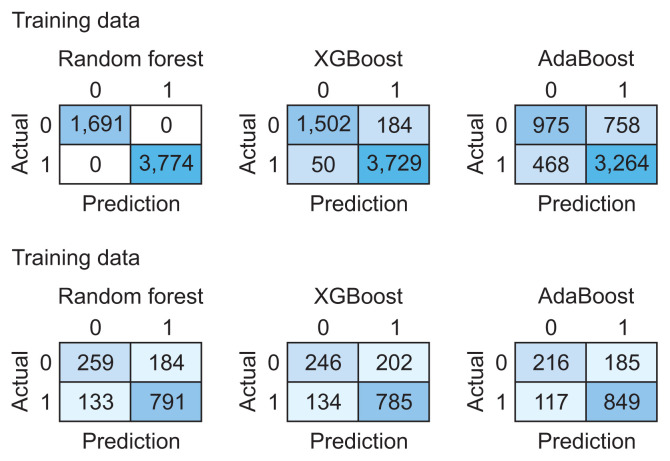
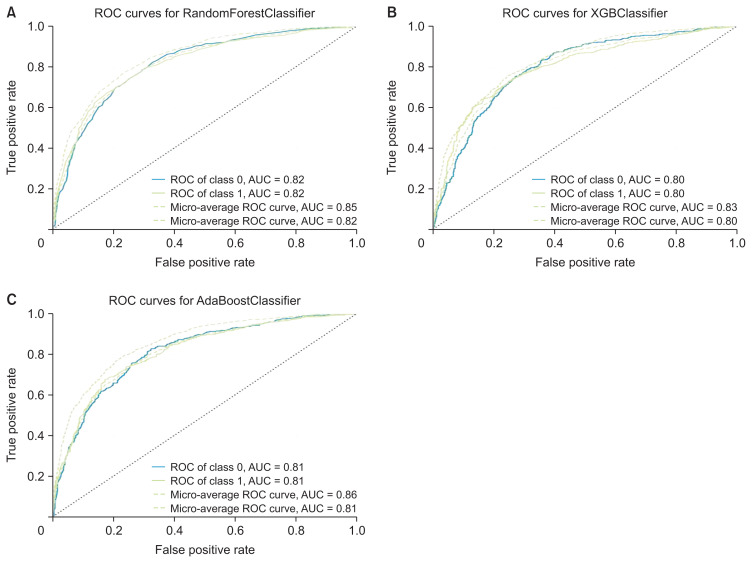
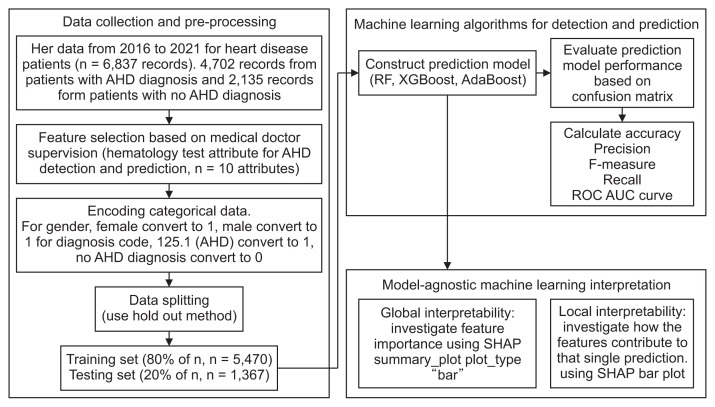
Methods: We used a hematology Electronic Health Record (EHR) with information on erythrocytes, hematocrit, hemoglobin, mean corpuscular hemoglobin, mean corpuscular hemoglobin concentration, leukocytes, thrombocytes, age, and sex. To detect and predict AHD, we explored random forest (RF), XGBoost, and AdaBoost models. We examined the prediction model results based on the confusion matrix and accuracy measures. We used the Shapley Additive exPlanations (SHAP) framework to interpret the ML model and quantify the contribution of features to predictions.
Results: Our study included data from 6,837 patients, with 4,702 records from patients diagnosed with AHD and 2,135 records from patients without an AHD diagnosis. AdaBoost outperformed RF and XGBoost, achieving an accuracy of 0.78, precision of 0.82, F1-score of 0.85, and recall of 0.88. According to the SHAP summary bar plot method, hemoglobin was the most important attribute for detecting and predicting AHD patients. The SHAP local interpretability bar plot revealed that hemoglobin and mean corpuscular hemoglobin concentration had positive impacts on AHD prediction based on a single observation.
Conclusions: ML models based on real clinical data can be used to predict AHD.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


