A Usha Ruby, J George Chellin Chandran, T J Swasthika Jain, B N Chaithanya, Renuka Patil
{"title":"RFFE - Random Forest Fuzzy Entropy for the classification of Diabetes Mellitus.","authors":"A Usha Ruby, J George Chellin Chandran, T J Swasthika Jain, B N Chaithanya, Renuka Patil","doi":"10.3934/publichealth.2023030","DOIUrl":null,"url":null,"abstract":"<p><p>Diabetes is a category of metabolic disease commonly known as a chronic illness. It causes the body to generate less insulin and raises blood sugar levels, leading to various issues and disrupting the functioning of organs, including the retinal, kidney and nerves. To prevent this, people with chronic illnesses require lifetime access to treatment. As a result, early diabetes detection is essential and might save many lives. Diagnosis of people at high risk of developing diabetes is utilized for preventing the disease in various aspects. This article presents a chronic illness prediction prototype based on a person's risk feature data to provide an early prediction for diabetes with Fuzzy Entropy random vectors that regulate the development of each tree in the Random Forest. The proposed prototype consists of data imputation, data sampling, feature selection, and various techniques to predict the disease, such as Fuzzy Entropy, Synthetic Minority Oversampling Technique (SMOTE), Convolutional Neural Network (CNN) with Stochastic Gradient Descent with Momentum (SGDM), Support Vector Machines (SVM), Classification and Regression Tree (CART), K-Nearest Neighbor (KNN), and Naïve Bayes (NB). This study uses the existing Pima Indian Diabetes (PID) dataset for diabetic disease prediction. The predictions' true/false positive/negative rate is investigated using the confusion matrix and the receiver operating characteristic area under the curve (ROCAUC). Findings on a PID dataset are compared with machine learning algorithms revealing that the proposed Random Forest Fuzzy Entropy (RFFE) is a valuable approach for diabetes prediction, with an accuracy of 98 percent.</p>","PeriodicalId":45684,"journal":{"name":"AIMS Public Health","volume":"10 2","pages":"422-442"},"PeriodicalIF":3.1000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10251052/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"AIMS Public Health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3934/publichealth.2023030","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
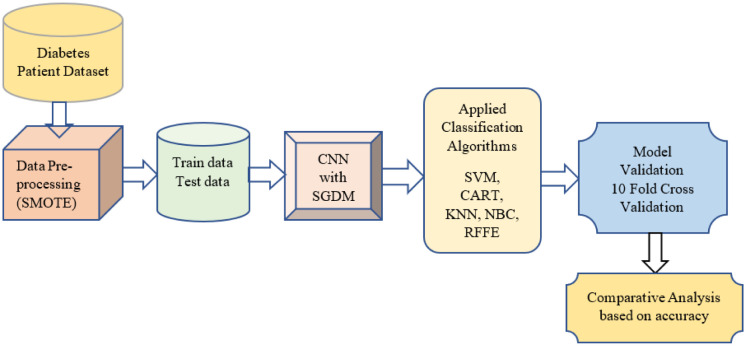
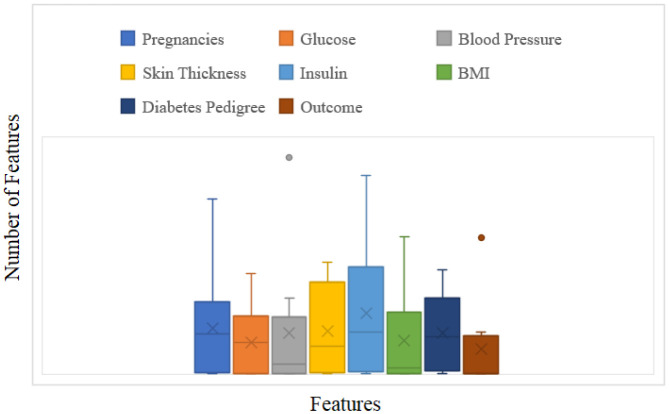
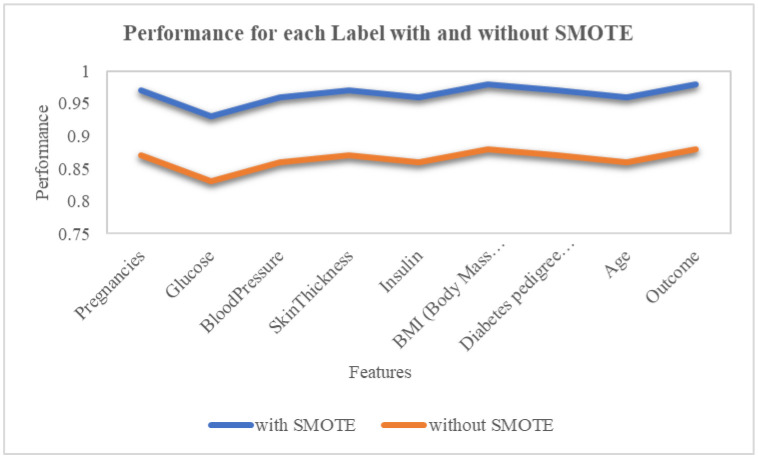
Diabetes is a category of metabolic disease commonly known as a chronic illness. It causes the body to generate less insulin and raises blood sugar levels, leading to various issues and disrupting the functioning of organs, including the retinal, kidney and nerves. To prevent this, people with chronic illnesses require lifetime access to treatment. As a result, early diabetes detection is essential and might save many lives. Diagnosis of people at high risk of developing diabetes is utilized for preventing the disease in various aspects. This article presents a chronic illness prediction prototype based on a person's risk feature data to provide an early prediction for diabetes with Fuzzy Entropy random vectors that regulate the development of each tree in the Random Forest. The proposed prototype consists of data imputation, data sampling, feature selection, and various techniques to predict the disease, such as Fuzzy Entropy, Synthetic Minority Oversampling Technique (SMOTE), Convolutional Neural Network (CNN) with Stochastic Gradient Descent with Momentum (SGDM), Support Vector Machines (SVM), Classification and Regression Tree (CART), K-Nearest Neighbor (KNN), and Naïve Bayes (NB). This study uses the existing Pima Indian Diabetes (PID) dataset for diabetic disease prediction. The predictions' true/false positive/negative rate is investigated using the confusion matrix and the receiver operating characteristic area under the curve (ROCAUC). Findings on a PID dataset are compared with machine learning algorithms revealing that the proposed Random Forest Fuzzy Entropy (RFFE) is a valuable approach for diabetes prediction, with an accuracy of 98 percent.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


