Tom Strating, Leila Shafiee Hanjani, Ida Tornvall, Ruth Hubbard, Ian A Scott
{"title":"Navigating the machine learning pipeline: a scoping review of inpatient delirium prediction models.","authors":"Tom Strating, Leila Shafiee Hanjani, Ida Tornvall, Ruth Hubbard, Ian A Scott","doi":"10.1136/bmjhci-2023-100767","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Early identification of inpatients at risk of developing delirium and implementing preventive measures could avoid up to 40% of delirium cases. Machine learning (ML)-based prediction models may enable risk stratification and targeted intervention, but establishing their current evolutionary status requires a scoping review of recent literature.</p><p><strong>Methods: </strong>We searched ten databases up to June 2022 for studies of ML-based delirium prediction models. Eligible criteria comprised: use of at least one ML prediction method in an adult hospital inpatient population; published in English; reporting at least one performance measure (area under receiver-operator curve (AUROC), sensitivity, specificity, positive or negative predictive value). Included models were categorised by their stage of maturation and assessed for performance, utility and user acceptance in clinical practice.</p><p><strong>Results: </strong>Among 921 screened studies, 39 met eligibility criteria. In-silico performance was consistently high (median AUROC: 0.85); however, only six articles (15.4%) reported external validation, revealing degraded performance (median AUROC: 0.75). Three studies (7.7%) of models deployed within clinical workflows reported high accuracy (median AUROC: 0.92) and high user acceptance.</p><p><strong>Discussion: </strong>ML models have potential to identify inpatients at risk of developing delirium before symptom onset. However, few models were externally validated and even fewer underwent prospective evaluation in clinical settings.</p><p><strong>Conclusion: </strong>This review confirms a rapidly growing body of research into using ML for predicting delirium risk in hospital settings. Our findings offer insights for both developers and clinicians into strengths and limitations of current ML delirium prediction applications aiming to support but not usurp clinician decision-making.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/ec/23/bmjhci-2023-100767.PMC10335592.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2023-100767","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Early identification of inpatients at risk of developing delirium and implementing preventive measures could avoid up to 40% of delirium cases. Machine learning (ML)-based prediction models may enable risk stratification and targeted intervention, but establishing their current evolutionary status requires a scoping review of recent literature.
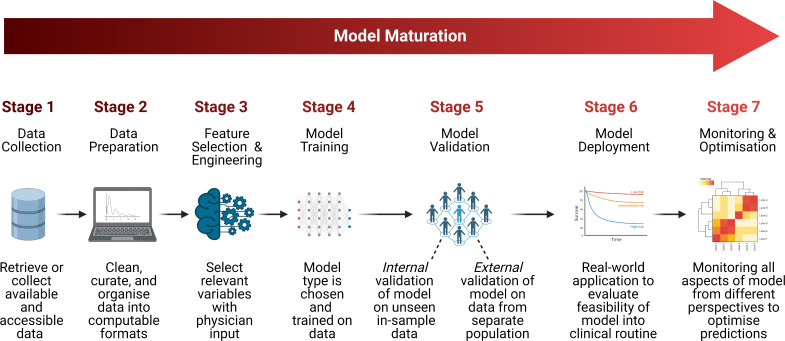
Methods: We searched ten databases up to June 2022 for studies of ML-based delirium prediction models. Eligible criteria comprised: use of at least one ML prediction method in an adult hospital inpatient population; published in English; reporting at least one performance measure (area under receiver-operator curve (AUROC), sensitivity, specificity, positive or negative predictive value). Included models were categorised by their stage of maturation and assessed for performance, utility and user acceptance in clinical practice.
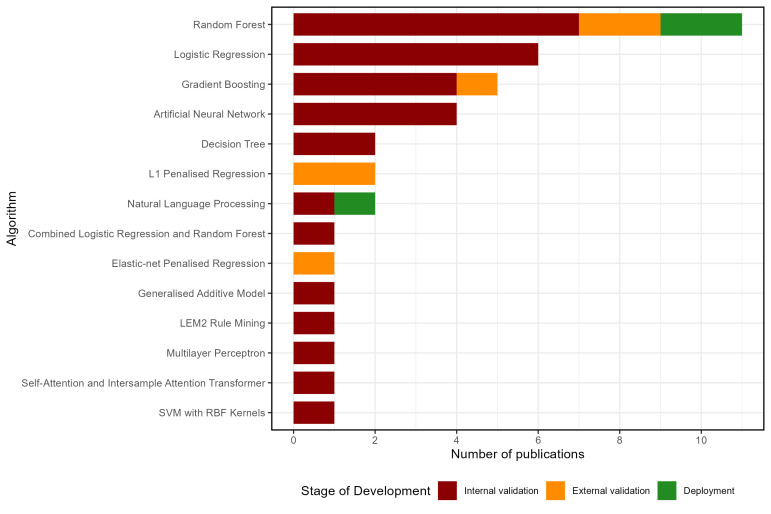
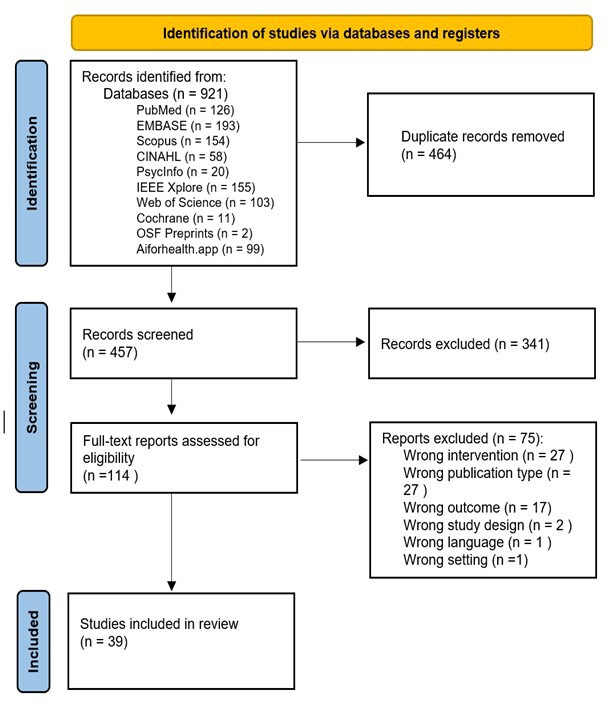
Results: Among 921 screened studies, 39 met eligibility criteria. In-silico performance was consistently high (median AUROC: 0.85); however, only six articles (15.4%) reported external validation, revealing degraded performance (median AUROC: 0.75). Three studies (7.7%) of models deployed within clinical workflows reported high accuracy (median AUROC: 0.92) and high user acceptance.
Discussion: ML models have potential to identify inpatients at risk of developing delirium before symptom onset. However, few models were externally validated and even fewer underwent prospective evaluation in clinical settings.
Conclusion: This review confirms a rapidly growing body of research into using ML for predicting delirium risk in hospital settings. Our findings offer insights for both developers and clinicians into strengths and limitations of current ML delirium prediction applications aiming to support but not usurp clinician decision-making.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


