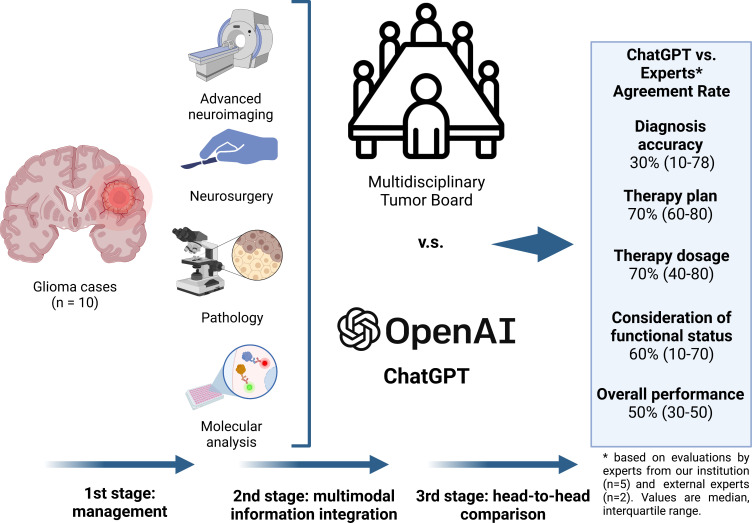
Julien Haemmerli, Lukas Sveikata, Aria Nouri, Adrien May, Kristof Egervari, Christian Freyschlag, Johannes A Lobrinus, Denis Migliorini, Shahan Momjian, Nicolae Sanda, Karl Schaller, Sebastien Tran, Jacky Yeung, Philippe Bijlenga
{"title":"ChatGPT in glioma adjuvant therapy decision making: ready to assume the role of a doctor in the tumour board?","authors":"Julien Haemmerli, Lukas Sveikata, Aria Nouri, Adrien May, Kristof Egervari, Christian Freyschlag, Johannes A Lobrinus, Denis Migliorini, Shahan Momjian, Nicolae Sanda, Karl Schaller, Sebastien Tran, Jacky Yeung, Philippe Bijlenga","doi":"10.1136/bmjhci-2023-100775","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To evaluate ChatGPT's performance in brain glioma adjuvant therapy decision-making.</p><p><strong>Methods: </strong>We randomly selected 10 patients with brain gliomas discussed at our institution's central nervous system tumour board (CNS TB). Patients' clinical status, surgical outcome, textual imaging information and immuno-pathology results were provided to ChatGPT V.3.5 and seven CNS tumour experts. The chatbot was asked to give the adjuvant treatment choice, and the regimen while considering the patient's functional status. The experts rated the artificial intelligence-based recommendations from 0 (complete disagreement) to 10 (complete agreement). An intraclass correlation coefficient agreement (ICC) was used to measure the inter-rater agreement.</p><p><strong>Results: </strong>Eight patients (80%) met the criteria for glioblastoma and two (20%) were low-grade gliomas. The experts rated the quality of ChatGPT recommendations as poor for diagnosis (median 3, IQR 1-7.8, ICC 0.9, 95% CI 0.7 to 1.0), good for treatment recommendation (7, IQR 6-8, ICC 0.8, 95% CI 0.4 to 0.9), good for therapy regimen (7, IQR 4-8, ICC 0.8, 95% CI 0.5 to 0.9), moderate for functional status consideration (6, IQR 1-7, ICC 0.7, 95% CI 0.3 to 0.9) and moderate for overall agreement with the recommendations (5, IQR 3-7, ICC 0.7, 95% CI 0.3 to 0.9). No differences were observed between the glioblastomas and low-grade glioma ratings.</p><p><strong>Conclusions: </strong>ChatGPT performed poorly in classifying glioma types but was good for adjuvant treatment recommendations as evaluated by CNS TB experts. Even though the ChatGPT lacks the precision to replace expert opinion, it may serve as a promising supplemental tool within a human-in-the-loop approach.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2023-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/8e/7e/bmjhci-2023-100775.PMC10314415.pdf","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2023-100775","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 9
Abstract
Objective: To evaluate ChatGPT's performance in brain glioma adjuvant therapy decision-making.
Methods: We randomly selected 10 patients with brain gliomas discussed at our institution's central nervous system tumour board (CNS TB). Patients' clinical status, surgical outcome, textual imaging information and immuno-pathology results were provided to ChatGPT V.3.5 and seven CNS tumour experts. The chatbot was asked to give the adjuvant treatment choice, and the regimen while considering the patient's functional status. The experts rated the artificial intelligence-based recommendations from 0 (complete disagreement) to 10 (complete agreement). An intraclass correlation coefficient agreement (ICC) was used to measure the inter-rater agreement.
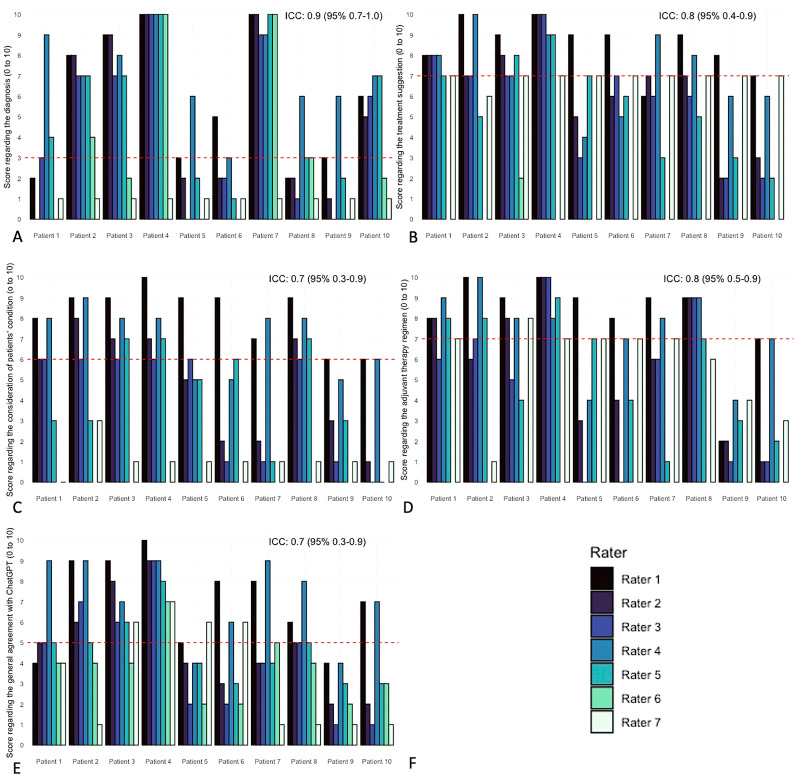
Results: Eight patients (80%) met the criteria for glioblastoma and two (20%) were low-grade gliomas. The experts rated the quality of ChatGPT recommendations as poor for diagnosis (median 3, IQR 1-7.8, ICC 0.9, 95% CI 0.7 to 1.0), good for treatment recommendation (7, IQR 6-8, ICC 0.8, 95% CI 0.4 to 0.9), good for therapy regimen (7, IQR 4-8, ICC 0.8, 95% CI 0.5 to 0.9), moderate for functional status consideration (6, IQR 1-7, ICC 0.7, 95% CI 0.3 to 0.9) and moderate for overall agreement with the recommendations (5, IQR 3-7, ICC 0.7, 95% CI 0.3 to 0.9). No differences were observed between the glioblastomas and low-grade glioma ratings.
Conclusions: ChatGPT performed poorly in classifying glioma types but was good for adjuvant treatment recommendations as evaluated by CNS TB experts. Even though the ChatGPT lacks the precision to replace expert opinion, it may serve as a promising supplemental tool within a human-in-the-loop approach.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


