Katie S Allen, Dan R Hood, Jonathan Cummins, Suranga Kasturi, Eneida A Mendonca, Joshua R Vest
{"title":"Natural language processing-driven state machines to extract social factors from unstructured clinical documentation.","authors":"Katie S Allen, Dan R Hood, Jonathan Cummins, Suranga Kasturi, Eneida A Mendonca, Joshua R Vest","doi":"10.1093/jamiaopen/ooad024","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This study sought to create natural language processing algorithms to extract the presence of social factors from clinical text in 3 areas: (1) housing, (2) financial, and (3) unemployment. For generalizability, finalized models were validated on data from a separate health system for generalizability.</p><p><strong>Materials and methods: </strong>Notes from 2 healthcare systems, representing a variety of note types, were utilized. To train models, the study utilized n-grams to identify keywords and implemented natural language processing (NLP) state machines across all note types. Manual review was conducted to determine performance. Sampling was based on a set percentage of notes, based on the prevalence of social need. Models were optimized over multiple training and evaluation cycles. Performance metrics were calculated using positive predictive value (PPV), negative predictive value, sensitivity, and specificity.</p><p><strong>Results: </strong>PPV for housing rose from 0.71 to 0.95 over 3 training runs. PPV for financial rose from 0.83 to 0.89 over 2 training iterations, while PPV for unemployment rose from 0.78 to 0.88 over 3 iterations. The test data resulted in PPVs of 0.94, 0.97, and 0.95 for housing, financial, and unemployment, respectively. Final specificity scores were 0.95, 0.97, and 0.95 for housing, financial, and unemployment, respectively.</p><p><strong>Discussion: </strong>We developed 3 rule-based NLP algorithms, trained across health systems. While this is a less sophisticated approach, the algorithms demonstrated a high degree of generalizability, maintaining >0.85 across all predictive performance metrics.</p><p><strong>Conclusion: </strong>The rule-based NLP algorithms demonstrated consistent performance in identifying 3 social factors within clinical text. These methods may be a part of a strategy to measure social factors within an institution.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 2","pages":"ooad024"},"PeriodicalIF":2.5000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/5b/2f/ooad024.PMC10112959.pdf","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad024","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 2
Abstract
Objective: This study sought to create natural language processing algorithms to extract the presence of social factors from clinical text in 3 areas: (1) housing, (2) financial, and (3) unemployment. For generalizability, finalized models were validated on data from a separate health system for generalizability.
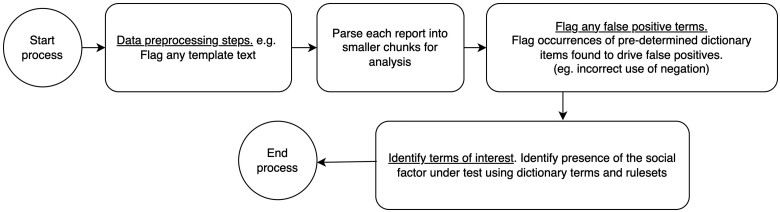
Materials and methods: Notes from 2 healthcare systems, representing a variety of note types, were utilized. To train models, the study utilized n-grams to identify keywords and implemented natural language processing (NLP) state machines across all note types. Manual review was conducted to determine performance. Sampling was based on a set percentage of notes, based on the prevalence of social need. Models were optimized over multiple training and evaluation cycles. Performance metrics were calculated using positive predictive value (PPV), negative predictive value, sensitivity, and specificity.
Results: PPV for housing rose from 0.71 to 0.95 over 3 training runs. PPV for financial rose from 0.83 to 0.89 over 2 training iterations, while PPV for unemployment rose from 0.78 to 0.88 over 3 iterations. The test data resulted in PPVs of 0.94, 0.97, and 0.95 for housing, financial, and unemployment, respectively. Final specificity scores were 0.95, 0.97, and 0.95 for housing, financial, and unemployment, respectively.
Discussion: We developed 3 rule-based NLP algorithms, trained across health systems. While this is a less sophisticated approach, the algorithms demonstrated a high degree of generalizability, maintaining >0.85 across all predictive performance metrics.
Conclusion: The rule-based NLP algorithms demonstrated consistent performance in identifying 3 social factors within clinical text. These methods may be a part of a strategy to measure social factors within an institution.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


