William D. Lees , Scott Christley , Ayelet Peres , Justin T. Kos , Brian Corrie , Duncan Ralph , Felix Breden , Lindsay G. Cowell , Gur Yaari , Martin Corcoran , Gunilla B. Karlsson Hedestam , Mats Ohlin , Andrew M. Collins , Corey T. Watson , Christian E. Busse , The AIRR Community
{"title":"AIRR community curation and standardised representation for immunoglobulin and T cell receptor germline sets","authors":"William D. Lees , Scott Christley , Ayelet Peres , Justin T. Kos , Brian Corrie , Duncan Ralph , Felix Breden , Lindsay G. Cowell , Gur Yaari , Martin Corcoran , Gunilla B. Karlsson Hedestam , Mats Ohlin , Andrew M. Collins , Corey T. Watson , Christian E. Busse , The AIRR Community","doi":"10.1016/j.immuno.2023.100025","DOIUrl":null,"url":null,"abstract":"<div><p>Analysis of an individual's immunoglobulin or T cell receptor gene repertoire can provide important insights into immune function. High-quality analysis of adaptive immune receptor repertoire sequencing data depends upon accurate and relatively complete germline sets, but current sets are known to be incomplete. Established processes for the review and systematic naming of receptor germline genes and alleles require specific evidence and data types, but the discovery landscape is rapidly changing. To exploit the potential of emerging data, and to provide the field with improved state-of-the-art germline sets, an intermediate approach is needed that will allow the rapid publication of consolidated sets derived from these emerging sources. These sets must use a consistent naming scheme and allow refinement and consolidation into genes as new information emerges. Name changes should be minimised, but, where changes occur, the naming history of a sequence must be traceable. Here we outline the current issues and opportunities for the curation of germline IG/TR genes and present a forward-looking data model for building out more robust germline sets that can dovetail with current established processes. We describe interoperability standards for germline sets, and an approach to transparency based on principles of findability, accessibility, interoperability, and reusability.</p></div>","PeriodicalId":73343,"journal":{"name":"Immunoinformatics (Amsterdam, Netherlands)","volume":"10 ","pages":"Article 100025"},"PeriodicalIF":0.0000,"publicationDate":"2023-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10310305/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Immunoinformatics (Amsterdam, Netherlands)","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667119023000058","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 1
Abstract
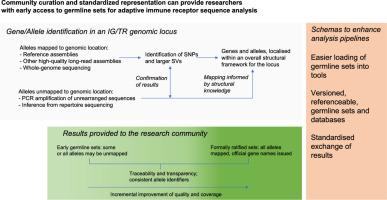
Analysis of an individual's immunoglobulin or T cell receptor gene repertoire can provide important insights into immune function. High-quality analysis of adaptive immune receptor repertoire sequencing data depends upon accurate and relatively complete germline sets, but current sets are known to be incomplete. Established processes for the review and systematic naming of receptor germline genes and alleles require specific evidence and data types, but the discovery landscape is rapidly changing. To exploit the potential of emerging data, and to provide the field with improved state-of-the-art germline sets, an intermediate approach is needed that will allow the rapid publication of consolidated sets derived from these emerging sources. These sets must use a consistent naming scheme and allow refinement and consolidation into genes as new information emerges. Name changes should be minimised, but, where changes occur, the naming history of a sequence must be traceable. Here we outline the current issues and opportunities for the curation of germline IG/TR genes and present a forward-looking data model for building out more robust germline sets that can dovetail with current established processes. We describe interoperability standards for germline sets, and an approach to transparency based on principles of findability, accessibility, interoperability, and reusability.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


