Efficient labelling for efficient deep learning: the benefit of a multiple-image-ranking method to generate high volume training data applied to ventricular slice level classification in cardiac MRI.
Sameer Zaman, Kavitha Vimalesvaran, James P Howard, Digby Chappell, Marta Varela, Nicholas S Peters, Darrel P Francis, Anil A Bharath, Nick W F Linton, Graham D Cole
{"title":"Efficient labelling for efficient deep learning: the benefit of a multiple-image-ranking method to generate high volume training data applied to ventricular slice level classification in cardiac MRI.","authors":"Sameer Zaman, Kavitha Vimalesvaran, James P Howard, Digby Chappell, Marta Varela, Nicholas S Peters, Darrel P Francis, Anil A Bharath, Nick W F Linton, Graham D Cole","doi":"10.21037/jmai-22-55","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Getting the most value from expert clinicians' limited labelling time is a major challenge for artificial intelligence (AI) development in clinical imaging. We present a novel method for ground-truth labelling of cardiac magnetic resonance imaging (CMR) image data by leveraging multiple clinician experts ranking multiple images on a single ordinal axis, rather than manual labelling of one image at a time. We apply this strategy to train a deep learning (DL) model to classify the anatomical position of CMR images. This allows the automated removal of slices that do not contain the left ventricular (LV) myocardium.</p><p><strong>Methods: </strong>Anonymised LV short-axis slices from 300 random scans (3,552 individual images) were extracted. Each image's anatomical position relative to the LV was labelled using two different strategies performed for 5 hours each: (I) 'one-image-at-a-time': each image labelled according to its position: 'too basal', 'LV', or 'too apical' individually by one of three experts; and (II) 'multiple-image-ranking': three independent experts ordered slices according to their relative position from 'most-basal' to 'most apical' in batches of eight until each image had been viewed at least 3 times. Two convolutional neural networks were trained for a three-way classification task (each model using data from one labelling strategy). The models' performance was evaluated by accuracy, F1-score, and area under the receiver operating characteristics curve (ROC AUC).</p><p><strong>Results: </strong>After excluding images with artefact, 3,323 images were labelled by both strategies. The model trained using labels from the 'multiple-image-ranking strategy' performed better than the model using the 'one-image-at-a-time' labelling strategy (accuracy 86% <i>vs.</i> 72%, P=0.02; F1-score 0.86 <i>vs.</i> 0.75; ROC AUC 0.95 <i>vs.</i> 0.86). For expert clinicians performing this task manually the intra-observer variability was low (Cohen's κ=0.90), but the inter-observer variability was higher (Cohen's κ=0.77).</p><p><strong>Conclusions: </strong>We present proof of concept that, given the same clinician labelling effort, comparing multiple images side-by-side using a 'multiple-image-ranking' strategy achieves ground truth labels for DL more accurately than by classifying images individually. We demonstrate a potential clinical application: the automatic removal of unrequired CMR images. This leads to increased efficiency by focussing human and machine attention on images which are needed to answer clinical questions.</p>","PeriodicalId":73815,"journal":{"name":"Journal of medical artificial intelligence","volume":"6 ","pages":"4"},"PeriodicalIF":0.0000,"publicationDate":"2023-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7614685/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of medical artificial intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.21037/jmai-22-55","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Getting the most value from expert clinicians' limited labelling time is a major challenge for artificial intelligence (AI) development in clinical imaging. We present a novel method for ground-truth labelling of cardiac magnetic resonance imaging (CMR) image data by leveraging multiple clinician experts ranking multiple images on a single ordinal axis, rather than manual labelling of one image at a time. We apply this strategy to train a deep learning (DL) model to classify the anatomical position of CMR images. This allows the automated removal of slices that do not contain the left ventricular (LV) myocardium.
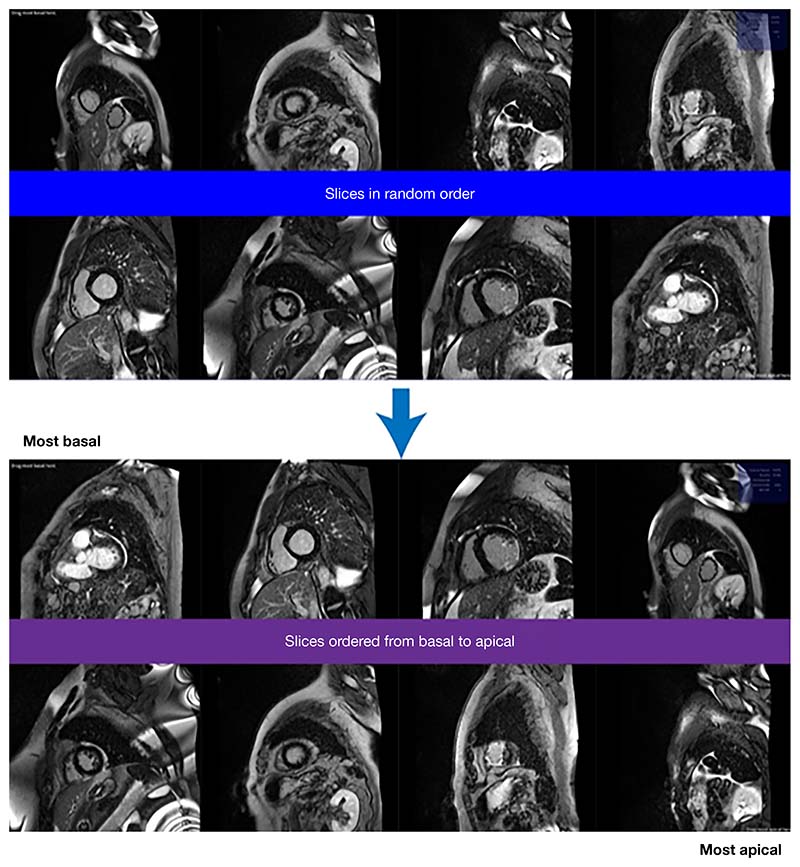
Methods: Anonymised LV short-axis slices from 300 random scans (3,552 individual images) were extracted. Each image's anatomical position relative to the LV was labelled using two different strategies performed for 5 hours each: (I) 'one-image-at-a-time': each image labelled according to its position: 'too basal', 'LV', or 'too apical' individually by one of three experts; and (II) 'multiple-image-ranking': three independent experts ordered slices according to their relative position from 'most-basal' to 'most apical' in batches of eight until each image had been viewed at least 3 times. Two convolutional neural networks were trained for a three-way classification task (each model using data from one labelling strategy). The models' performance was evaluated by accuracy, F1-score, and area under the receiver operating characteristics curve (ROC AUC).
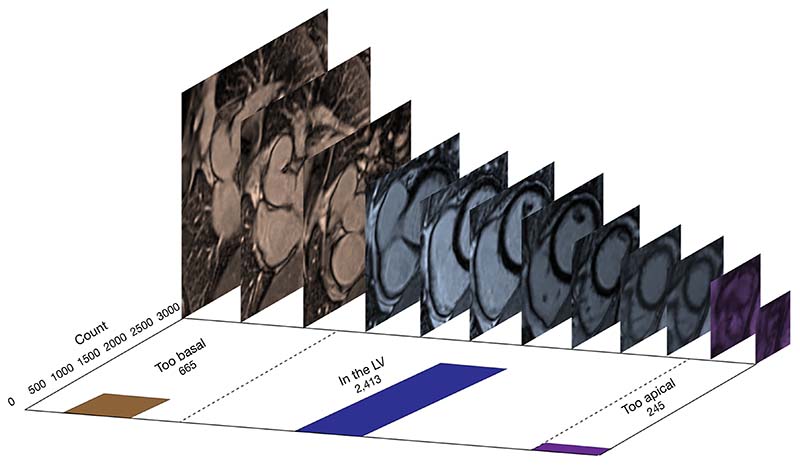
Results: After excluding images with artefact, 3,323 images were labelled by both strategies. The model trained using labels from the 'multiple-image-ranking strategy' performed better than the model using the 'one-image-at-a-time' labelling strategy (accuracy 86% vs. 72%, P=0.02; F1-score 0.86 vs. 0.75; ROC AUC 0.95 vs. 0.86). For expert clinicians performing this task manually the intra-observer variability was low (Cohen's κ=0.90), but the inter-observer variability was higher (Cohen's κ=0.77).
Conclusions: We present proof of concept that, given the same clinician labelling effort, comparing multiple images side-by-side using a 'multiple-image-ranking' strategy achieves ground truth labels for DL more accurately than by classifying images individually. We demonstrate a potential clinical application: the automatic removal of unrequired CMR images. This leads to increased efficiency by focussing human and machine attention on images which are needed to answer clinical questions.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


