Shubam Sachdeva, Haoyao Ruan, Ghassan Hamarneh, Dawn M Behne, Allard Jongman, Joan A Sereno, Yue Wang
{"title":"Plain-to-clear speech video conversion for enhanced intelligibility.","authors":"Shubam Sachdeva, Haoyao Ruan, Ghassan Hamarneh, Dawn M Behne, Allard Jongman, Joan A Sereno, Yue Wang","doi":"10.1007/s10772-023-10018-z","DOIUrl":null,"url":null,"abstract":"<p><p>Clearly articulated speech, relative to plain-style speech, has been shown to improve intelligibility. We examine if visible speech cues in video only can be systematically modified to enhance clear-speech visual features and improve intelligibility. We extract clear-speech visual features of English words varying in vowels produced by multiple male and female talkers. Via a frame-by-frame image-warping based video generation method with a controllable parameter (displacement factor), we apply the extracted clear-speech visual features to videos of plain speech to synthesize clear speech videos. We evaluate the generated videos using a robust, state of the art AI Lip Reader as well as human intelligibility testing. The contributions of this study are: (1) we successfully extract relevant visual cues for video modifications across speech styles, and have achieved enhanced intelligibility for AI; (2) this work suggests that universal talker-independent clear-speech features may be utilized to modify any talker's visual speech style; (3) we introduce \"displacement factor\" as a way of systematically scaling the magnitude of displacement modifications between speech styles; and (4) the high definition generated videos make them ideal candidates for human-centric intelligibility and perceptual training studies.</p>","PeriodicalId":14305,"journal":{"name":"International Journal of Speech Technology","volume":"26 1","pages":"163-184"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10042924/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Speech Technology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10772-023-10018-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Arts and Humanities","Score":null,"Total":0}
引用次数: 0
Abstract
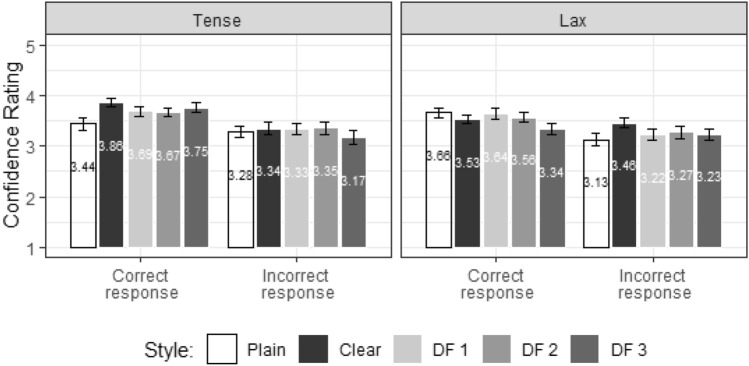
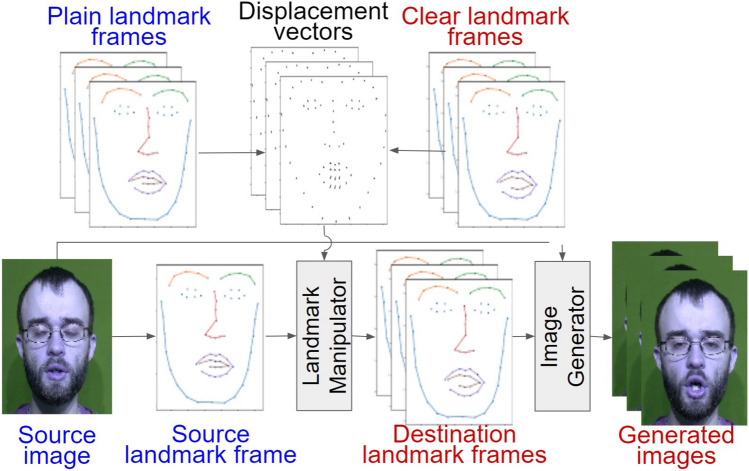
Clearly articulated speech, relative to plain-style speech, has been shown to improve intelligibility. We examine if visible speech cues in video only can be systematically modified to enhance clear-speech visual features and improve intelligibility. We extract clear-speech visual features of English words varying in vowels produced by multiple male and female talkers. Via a frame-by-frame image-warping based video generation method with a controllable parameter (displacement factor), we apply the extracted clear-speech visual features to videos of plain speech to synthesize clear speech videos. We evaluate the generated videos using a robust, state of the art AI Lip Reader as well as human intelligibility testing. The contributions of this study are: (1) we successfully extract relevant visual cues for video modifications across speech styles, and have achieved enhanced intelligibility for AI; (2) this work suggests that universal talker-independent clear-speech features may be utilized to modify any talker's visual speech style; (3) we introduce "displacement factor" as a way of systematically scaling the magnitude of displacement modifications between speech styles; and (4) the high definition generated videos make them ideal candidates for human-centric intelligibility and perceptual training studies.
期刊介绍:
The International Journal of Speech Technology is a research journal that focuses on speech technology and its applications. It promotes research and description on all aspects of speech input and output, including theory, experiment, testing, base technology, applications. The journal is an international forum for the dissemination of research related to the applications of speech technology as well as to the technology itself as it relates to real-world applications. Articles describing original work in all aspects of speech technology are included. Sample topics include but are not limited to the following: applications employing digitized speech, synthesized speech or automatic speech recognition technological issues of speech input or output human factors, intelligent interfaces, robust applications integration of aspects of artificial intelligence and natural language processing international and local language implementations of speech synthesis and recognition development of new algorithms interface description techniques, tools and languages testing of intelligibility, naturalness and accuracy computational issues in speech technology software development tools speech-enabled robotics speech technology as a diagnostic tool for treating language disorders voice technology for managing serious laryngeal disabilities the use of speech in multimedia This is the only journal which presents papers on both the base technology and theory as well as all varieties of applications. It encompasses all aspects of the three major technologies: text-to-speech synthesis, automatic speech recognition and stored (digitized) speech.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


