{"title":"A novel centroid based sentence classification approach for extractive summarization of COVID-19 news reports.","authors":"Sumanta Banerjee, Shyamapada Mukherjee, Sivaji Bandyopadhyay","doi":"10.1007/s41870-023-01221-x","DOIUrl":null,"url":null,"abstract":"<p><p>A COVID-19 news covers subtopics like infections, deaths, the economy, jobs, and more. The proposed method generates a news summary based on the subtopics of a reader's interest. It extracts a centroid having the lexical pattern of the sentences on those subtopics by the frequently used words in them. The centroid is then used as a query in the vector space model (VSM) for sentence classification and extraction, producing a query focused summarization (QFS) of the documents. Three approaches, TF-IDF, word vector averaging, and auto-encoder are experimented to generate sentence embedding that are used in VSM. These embeddings are ranked depending on their similarities with the query embedding. A Novel approach has been introduced to find the value for the similarity parameter using a supervised technique to classify the sentences. Finally, the performance of the method has been assessed in two different ways. All the sentences of the dataset are considered together in the first assessment and in the second, each document wise group of sentences is considered separately using fivefold cross-validation. The proposed method has achieved a minimum of 0.60 to a maximum of 0.63 mean F1 scores with the three sentence encoding approaches on the test dataset.</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":"15 4","pages":"1789-1801"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10036244/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-023-01221-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/3/24 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
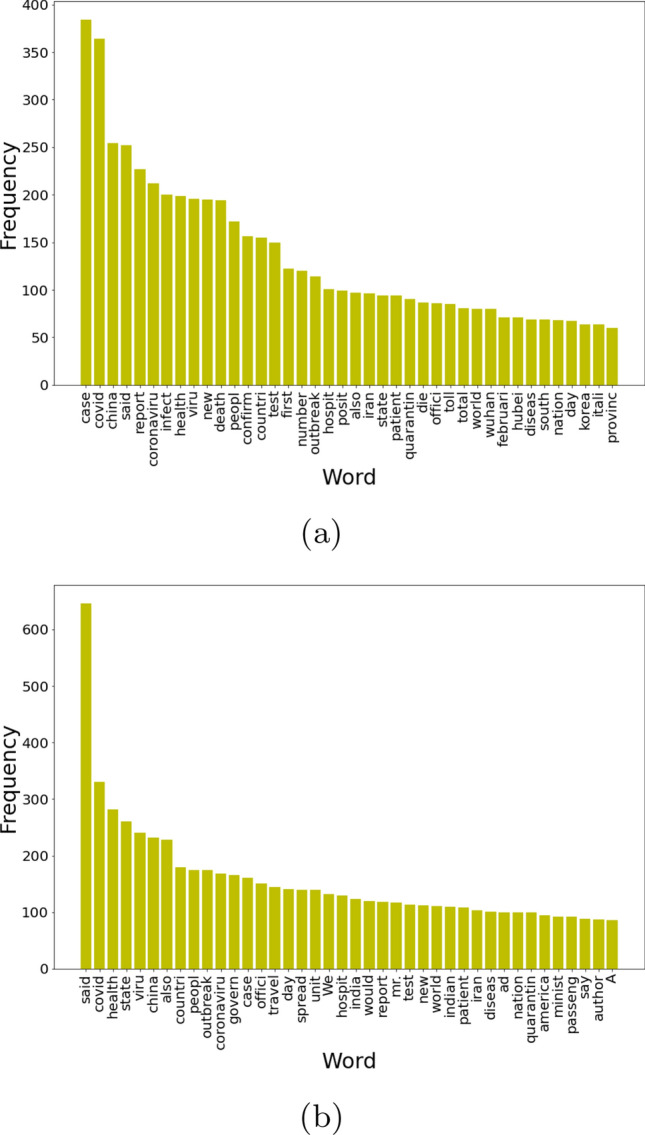
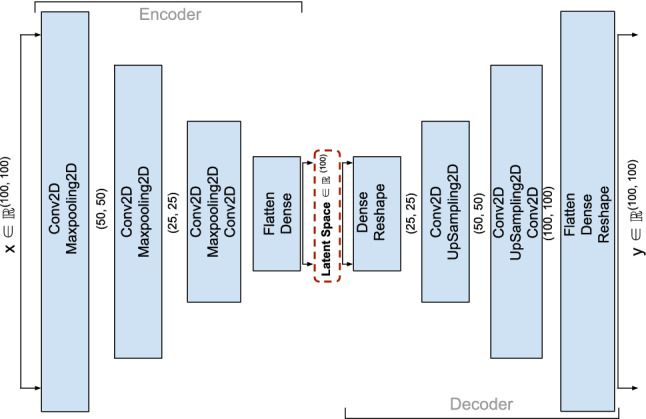
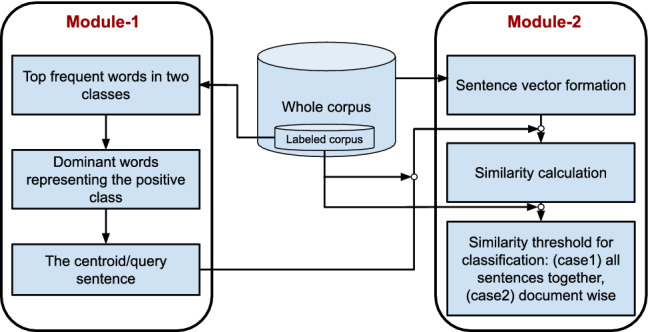
A COVID-19 news covers subtopics like infections, deaths, the economy, jobs, and more. The proposed method generates a news summary based on the subtopics of a reader's interest. It extracts a centroid having the lexical pattern of the sentences on those subtopics by the frequently used words in them. The centroid is then used as a query in the vector space model (VSM) for sentence classification and extraction, producing a query focused summarization (QFS) of the documents. Three approaches, TF-IDF, word vector averaging, and auto-encoder are experimented to generate sentence embedding that are used in VSM. These embeddings are ranked depending on their similarities with the query embedding. A Novel approach has been introduced to find the value for the similarity parameter using a supervised technique to classify the sentences. Finally, the performance of the method has been assessed in two different ways. All the sentences of the dataset are considered together in the first assessment and in the second, each document wise group of sentences is considered separately using fivefold cross-validation. The proposed method has achieved a minimum of 0.60 to a maximum of 0.63 mean F1 scores with the three sentence encoding approaches on the test dataset.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


