Yvette Pyne, Yik Ming Wong, Haishuo Fang, Edwin Simpson
{"title":"Analysis of 'One in a Million' primary care consultation conversations using natural language processing.","authors":"Yvette Pyne, Yik Ming Wong, Haishuo Fang, Edwin Simpson","doi":"10.1136/bmjhci-2022-100659","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Modern patient electronic health records form a core part of primary care; they contain both clinical codes and free text entered by the clinician. Natural language processing (NLP) could be employed to generate these records through 'listening' to a consultation conversation.</p><p><strong>Objectives: </strong>This study develops and assesses several text classifiers for identifying clinical codes for primary care consultations based on the doctor-patient conversation. We evaluate the possibility of training classifiers using medical code descriptions, and the benefits of processing transcribed speech from patients as well as doctors. The study also highlights steps for improving future classifiers.</p><p><strong>Methods: </strong>Using verbatim transcripts of 239 primary care consultation conversations (the 'One in a Million' dataset) and novel additional datasets for distant supervision, we trained NLP classifiers (naïve Bayes, support vector machine, nearest centroid, a conventional BERT classifier and few-shot BERT approaches) to identify the International Classification of Primary Care-2 clinical codes associated with each consultation.</p><p><strong>Results: </strong>Of all models tested, a fine-tuned BERT classifier was the best performer. Distant supervision improved the model's performance (F1 score over 16 classes) from 0.45 with conventional supervision with 191 labelled transcripts to 0.51. Incorporating patients' speech in addition to clinician's speech increased the BERT classifier's performance from 0.45 to 0.55 F1 (p=0.01, paired bootstrap test).</p><p><strong>Conclusions: </strong>Our findings demonstrate that NLP classifiers can be trained to identify clinical area(s) being discussed in a primary care consultation from audio transcriptions; this could represent an important step towards a smart digital assistant in the consultation room.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2023-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10151863/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2022-100659","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 1
Abstract
Background: Modern patient electronic health records form a core part of primary care; they contain both clinical codes and free text entered by the clinician. Natural language processing (NLP) could be employed to generate these records through 'listening' to a consultation conversation.
Objectives: This study develops and assesses several text classifiers for identifying clinical codes for primary care consultations based on the doctor-patient conversation. We evaluate the possibility of training classifiers using medical code descriptions, and the benefits of processing transcribed speech from patients as well as doctors. The study also highlights steps for improving future classifiers.
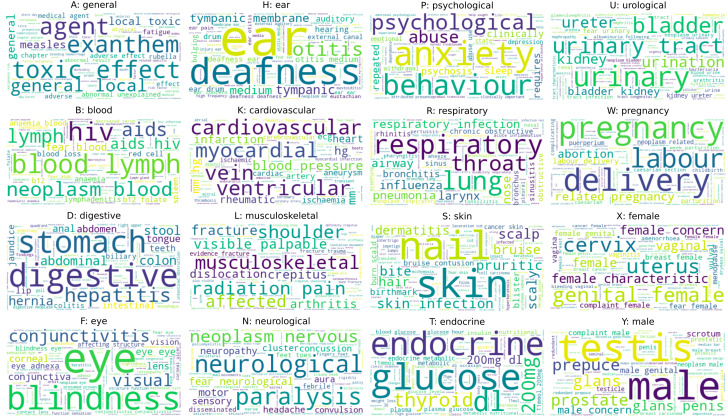
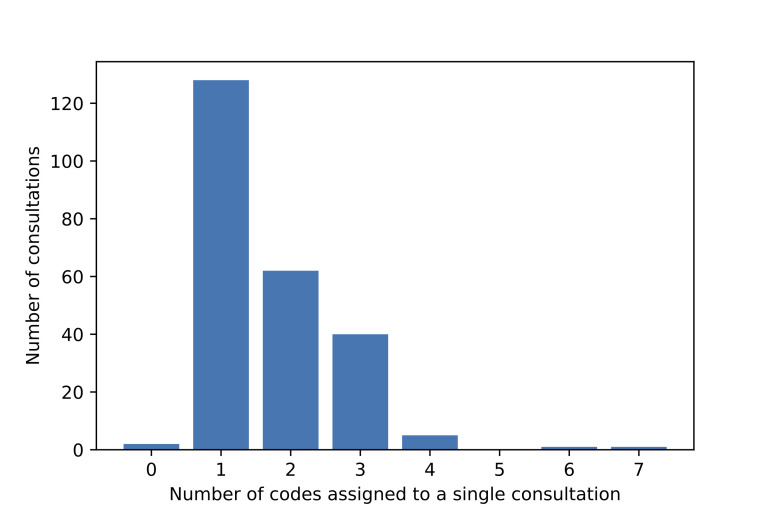
Methods: Using verbatim transcripts of 239 primary care consultation conversations (the 'One in a Million' dataset) and novel additional datasets for distant supervision, we trained NLP classifiers (naïve Bayes, support vector machine, nearest centroid, a conventional BERT classifier and few-shot BERT approaches) to identify the International Classification of Primary Care-2 clinical codes associated with each consultation.
Results: Of all models tested, a fine-tuned BERT classifier was the best performer. Distant supervision improved the model's performance (F1 score over 16 classes) from 0.45 with conventional supervision with 191 labelled transcripts to 0.51. Incorporating patients' speech in addition to clinician's speech increased the BERT classifier's performance from 0.45 to 0.55 F1 (p=0.01, paired bootstrap test).
Conclusions: Our findings demonstrate that NLP classifiers can be trained to identify clinical area(s) being discussed in a primary care consultation from audio transcriptions; this could represent an important step towards a smart digital assistant in the consultation room.
背景:现代患者电子病历是初级保健的核心部分;它们包含临床代码和临床医生输入的免费文本。自然语言处理(NLP)可以通过“聆听”咨询对话来生成这些记录。目的:本研究开发和评估了几个文本分类器,用于识别基于医患对话的初级保健咨询的临床代码。我们评估了使用医疗代码描述训练分类器的可能性,以及处理来自患者和医生的转录语音的好处。该研究还强调了改进未来分类器的步骤。方法:使用239个初级保健咨询对话的逐字记录(“百万分之一”数据集)和用于远程监督的新型额外数据集,我们训练了NLP分类器(naïve贝叶斯、支持向量机、最近质心、传统BERT分类器和几次BERT方法)来识别与每次咨询相关的国际初级保健分类-2临床代码。结果:在所有测试的模型中,经过微调的BERT分类器表现最好。远程监督将模型的性能(超过16个类别的F1分数)从191个标记转录本的常规监督的0.45提高到0.51。除了临床医生的语音外,合并患者的语音使BERT分类器的性能从0.45 F1提高到0.55 F1 (p=0.01,配对引导检验)。结论:我们的研究结果表明,NLP分类器可以通过训练来识别初级保健咨询中讨论的临床领域;这可能是向诊室智能数字助理迈出的重要一步。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


