{"title":"Barcode-free multiplex plasmid sequencing using Bayesian analysis and nanopore sequencing.","authors":"Masaaki Uematsu, Jeremy M Baskin","doi":"10.1101/2023.04.12.536413","DOIUrl":null,"url":null,"abstract":"<p><p>Plasmid construction is central to life science research, and sequence verification is arguably its costliest step. Long-read sequencing has emerged as a competitor to Sanger sequencing, with the principal benefit that whole plasmids can be sequenced in a single run. Nevertheless, the current cost of nanopore sequencing is still prohibitive for routine sequencing during plasmid construction. We develop a computational approach termed Simple Algorithm for Very Efficient Multiplexing of Oxford Nanopore Experiments for You (SAVEMONEY) that guides researchers to mix multiple plasmids and subsequently computationally de-mixes the resultant sequences. SAVEMONEY defines optimal mixtures in a pre-survey step, and following sequencing, executes a post-analysis workflow involving sequence classification, alignment, and consensus determination. By using Bayesian analysis with prior probability of expected plasmid construction error rate, high-confidence sequences can be obtained for each plasmid in the mixture. Plasmids differing by as little as two bases can be mixed for submission as a single sample for nanopore sequencing, and routine multiplexing of even six plasmids per 180 reads can still maintain high accuracy of consensus sequencing. SAVEMONEY should further democratize whole-plasmid sequencing by nanopore and related technologies, driving down the effective cost of whole-plasmid sequencing to lower than that of a single Sanger sequencing run.</p>","PeriodicalId":72407,"journal":{"name":"bioRxiv : the preprint server for biology","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-02-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/14/e4/nihpp-2023.04.12.536413v2.PMC10120676.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"bioRxiv : the preprint server for biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2023.04.12.536413","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
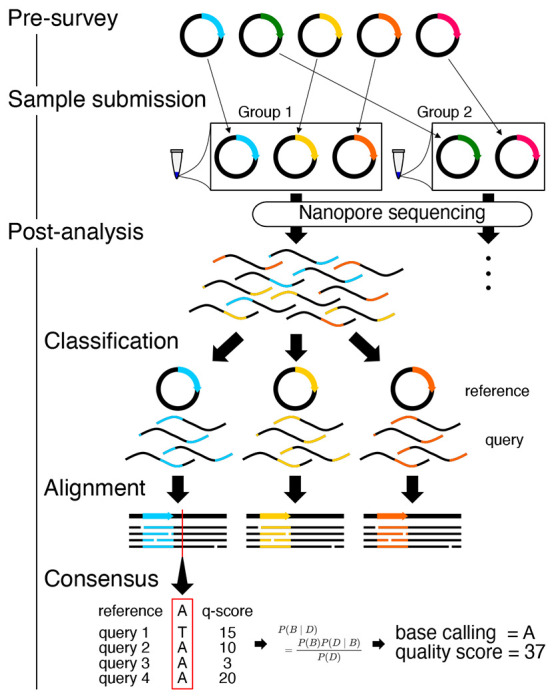
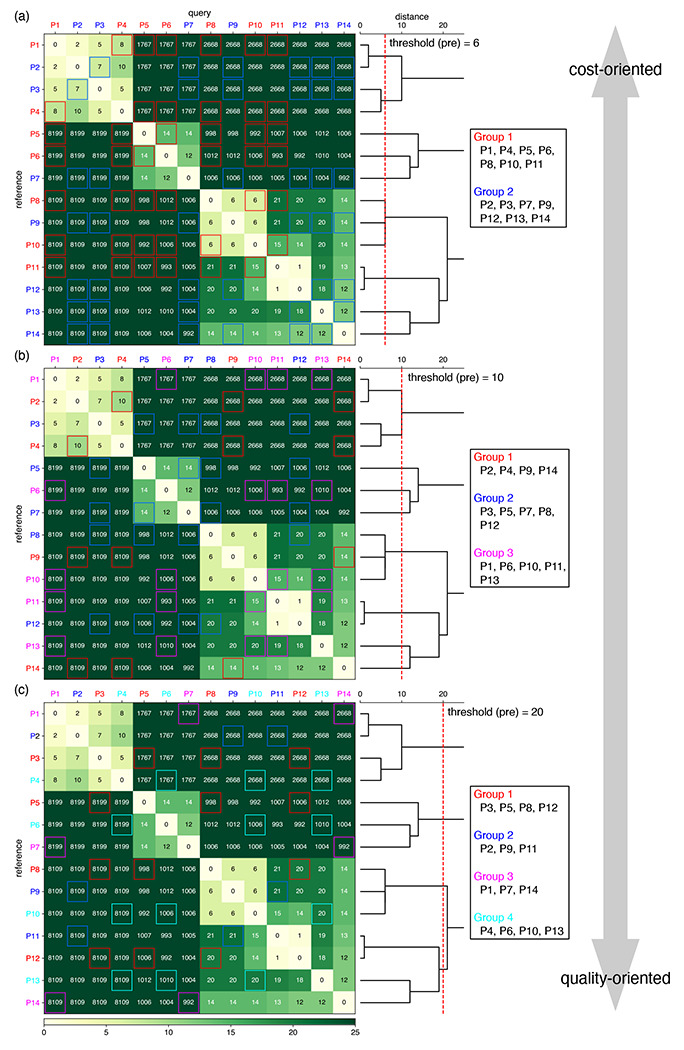
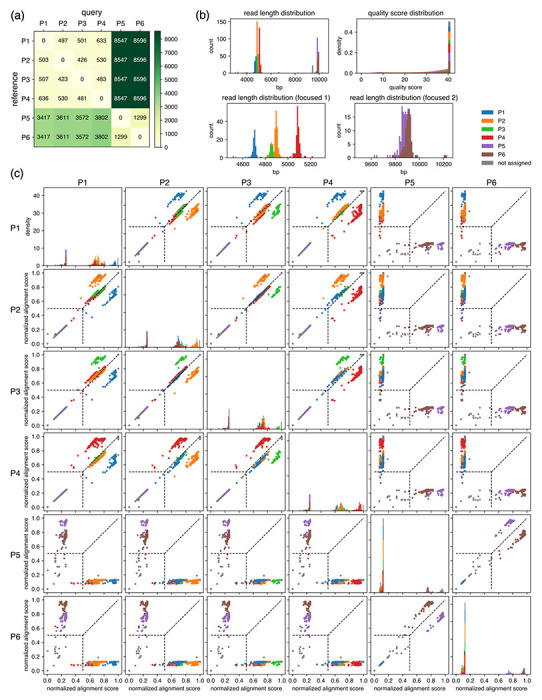
Plasmid construction is central to life science research, and sequence verification is arguably its costliest step. Long-read sequencing has emerged as a competitor to Sanger sequencing, with the principal benefit that whole plasmids can be sequenced in a single run. Nevertheless, the current cost of nanopore sequencing is still prohibitive for routine sequencing during plasmid construction. We develop a computational approach termed Simple Algorithm for Very Efficient Multiplexing of Oxford Nanopore Experiments for You (SAVEMONEY) that guides researchers to mix multiple plasmids and subsequently computationally de-mixes the resultant sequences. SAVEMONEY defines optimal mixtures in a pre-survey step, and following sequencing, executes a post-analysis workflow involving sequence classification, alignment, and consensus determination. By using Bayesian analysis with prior probability of expected plasmid construction error rate, high-confidence sequences can be obtained for each plasmid in the mixture. Plasmids differing by as little as two bases can be mixed for submission as a single sample for nanopore sequencing, and routine multiplexing of even six plasmids per 180 reads can still maintain high accuracy of consensus sequencing. SAVEMONEY should further democratize whole-plasmid sequencing by nanopore and related technologies, driving down the effective cost of whole-plasmid sequencing to lower than that of a single Sanger sequencing run.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


