{"title":"A self-inspected adaptive SMOTE algorithm (SASMOTE) for highly imbalanced data classification in healthcare.","authors":"Tanapol Kosolwattana, Chenang Liu, Renjie Hu, Shizhong Han, Hua Chen, Ying Lin","doi":"10.1186/s13040-023-00330-4","DOIUrl":null,"url":null,"abstract":"<p><p>In many healthcare applications, datasets for classification may be highly imbalanced due to the rare occurrence of target events such as disease onset. The SMOTE (Synthetic Minority Over-sampling Technique) algorithm has been developed as an effective resampling method for imbalanced data classification by oversampling samples from the minority class. However, samples generated by SMOTE may be ambiguous, low-quality and non-separable with the majority class. To enhance the quality of generated samples, we proposed a novel self-inspected adaptive SMOTE (SASMOTE) model that leverages an adaptive nearest neighborhood selection algorithm to identify the \"visible\" nearest neighbors, which are used to generate samples likely to fall into the minority class. To further enhance the quality of the generated samples, an uncertainty elimination via self-inspection approach is introduced in the proposed SASMOTE model. Its objective is to filter out the generated samples that are highly uncertain and inseparable with the majority class. The effectiveness of the proposed algorithm is compared with existing SMOTE-based algorithms and demonstrated through two real-world case studies in healthcare, including risk gene discovery and fatal congenital heart disease prediction. By generating the higher quality synthetic samples, the proposed algorithm is able to help achieve better prediction performance (in terms of F1 score) on average compared to the other methods, which is promising to enhance the usability of machine learning models on highly imbalanced healthcare data.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"15"},"PeriodicalIF":4.0000,"publicationDate":"2023-04-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131309/pdf/","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00330-4","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 4
Abstract
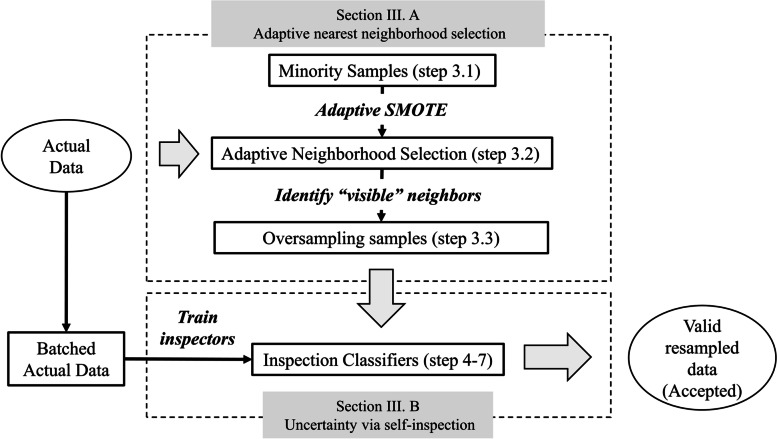
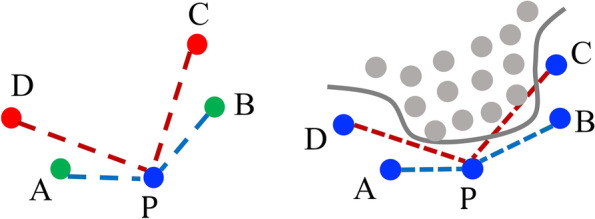
In many healthcare applications, datasets for classification may be highly imbalanced due to the rare occurrence of target events such as disease onset. The SMOTE (Synthetic Minority Over-sampling Technique) algorithm has been developed as an effective resampling method for imbalanced data classification by oversampling samples from the minority class. However, samples generated by SMOTE may be ambiguous, low-quality and non-separable with the majority class. To enhance the quality of generated samples, we proposed a novel self-inspected adaptive SMOTE (SASMOTE) model that leverages an adaptive nearest neighborhood selection algorithm to identify the "visible" nearest neighbors, which are used to generate samples likely to fall into the minority class. To further enhance the quality of the generated samples, an uncertainty elimination via self-inspection approach is introduced in the proposed SASMOTE model. Its objective is to filter out the generated samples that are highly uncertain and inseparable with the majority class. The effectiveness of the proposed algorithm is compared with existing SMOTE-based algorithms and demonstrated through two real-world case studies in healthcare, including risk gene discovery and fatal congenital heart disease prediction. By generating the higher quality synthetic samples, the proposed algorithm is able to help achieve better prediction performance (in terms of F1 score) on average compared to the other methods, which is promising to enhance the usability of machine learning models on highly imbalanced healthcare data.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


