{"title":"Effects of influential points and sample size on the selection and replicability of multivariable fractional polynomial models.","authors":"Willi Sauerbrei, Edwin Kipruto, James Balmford","doi":"10.1186/s41512-023-00145-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The multivariable fractional polynomial (MFP) approach combines variable selection using backward elimination with a function selection procedure (FSP) for fractional polynomial (FP) functions. It is a relatively simple approach which can be easily understood without advanced training in statistical modeling. For continuous variables, a closed test procedure is used to decide between no effect, linear, FP1, or FP2 functions. Influential points (IPs) and small sample sizes can both have a strong impact on a selected function and MFP model.</p><p><strong>Methods: </strong>We used simulated data with six continuous and four categorical predictors to illustrate approaches which can help to identify IPs with an influence on function selection and the MFP model. Approaches use leave-one or two-out and two related techniques for a multivariable assessment. In eight subsamples, we also investigated the effects of sample size and model replicability, the latter by using three non-overlapping subsamples with the same sample size. For better illustration, a structured profile was used to provide an overview of all analyses conducted.</p><p><strong>Results: </strong>The results showed that one or more IPs can drive the functions and models selected. In addition, with a small sample size, MFP was not able to detect some non-linear functions and the selected model differed substantially from the true underlying model. However, when the sample size was relatively large and regression diagnostics were carefully conducted, MFP selected functions or models that were similar to the underlying true model.</p><p><strong>Conclusions: </strong>For smaller sample size, IPs and low power are important reasons that the MFP approach may not be able to identify underlying functional relationships for continuous variables and selected models might differ substantially from the true model. However, for larger sample sizes, a carefully conducted MFP analysis is often a suitable way to select a multivariable regression model which includes continuous variables. In such a case, MFP can be the preferred approach to derive a multivariable descriptive model.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":"7 1","pages":"7"},"PeriodicalIF":2.6000,"publicationDate":"2023-04-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10111698/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-023-00145-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
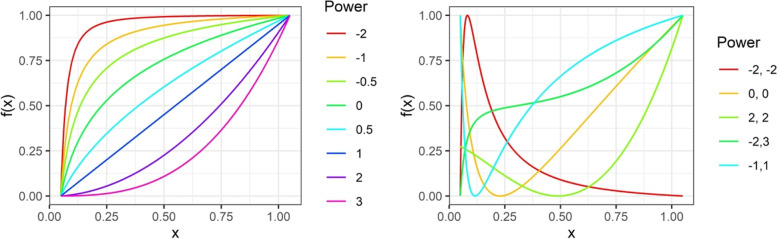
Background: The multivariable fractional polynomial (MFP) approach combines variable selection using backward elimination with a function selection procedure (FSP) for fractional polynomial (FP) functions. It is a relatively simple approach which can be easily understood without advanced training in statistical modeling. For continuous variables, a closed test procedure is used to decide between no effect, linear, FP1, or FP2 functions. Influential points (IPs) and small sample sizes can both have a strong impact on a selected function and MFP model.
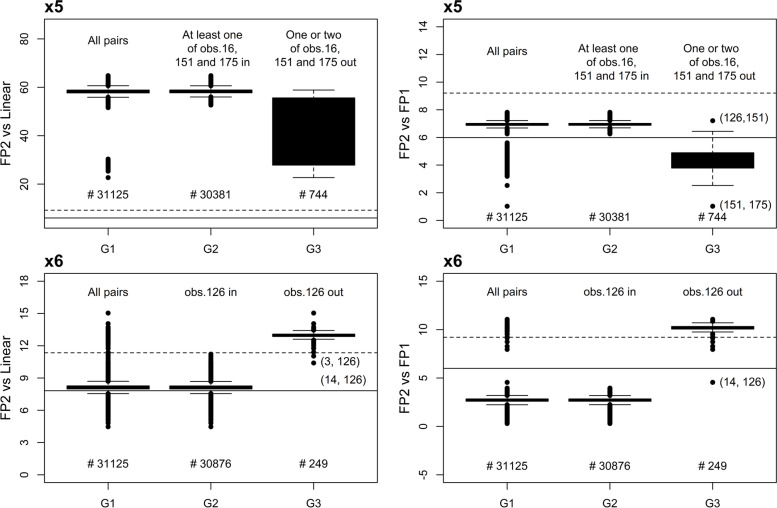
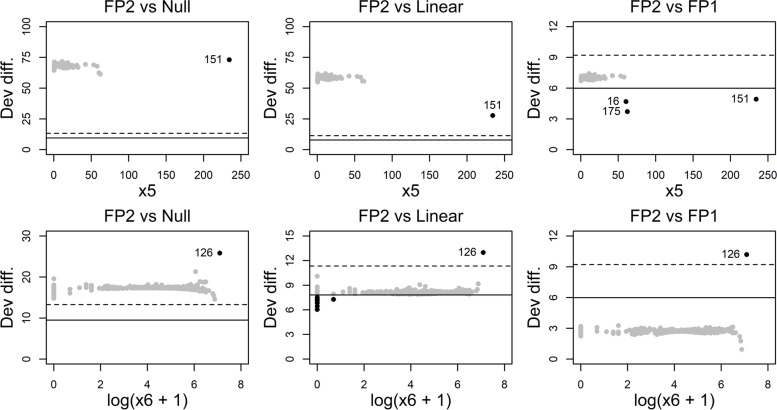
Methods: We used simulated data with six continuous and four categorical predictors to illustrate approaches which can help to identify IPs with an influence on function selection and the MFP model. Approaches use leave-one or two-out and two related techniques for a multivariable assessment. In eight subsamples, we also investigated the effects of sample size and model replicability, the latter by using three non-overlapping subsamples with the same sample size. For better illustration, a structured profile was used to provide an overview of all analyses conducted.
Results: The results showed that one or more IPs can drive the functions and models selected. In addition, with a small sample size, MFP was not able to detect some non-linear functions and the selected model differed substantially from the true underlying model. However, when the sample size was relatively large and regression diagnostics were carefully conducted, MFP selected functions or models that were similar to the underlying true model.
Conclusions: For smaller sample size, IPs and low power are important reasons that the MFP approach may not be able to identify underlying functional relationships for continuous variables and selected models might differ substantially from the true model. However, for larger sample sizes, a carefully conducted MFP analysis is often a suitable way to select a multivariable regression model which includes continuous variables. In such a case, MFP can be the preferred approach to derive a multivariable descriptive model.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


