Miguel Pedrera-Jiménez, Noelia García-Barrio, Paula Rubio-Mayo, Alberto Tato-Gómez, Juan Luis Cruz-Bermúdez, José Luis Bernal-Sobrino, Adolfo Muñoz-Carrero, Pablo Serrano-Balazote
{"title":"TransformEHRs: a flexible methodology for building transparent ETL processes for EHR reuse.","authors":"Miguel Pedrera-Jiménez, Noelia García-Barrio, Paula Rubio-Mayo, Alberto Tato-Gómez, Juan Luis Cruz-Bermúdez, José Luis Bernal-Sobrino, Adolfo Muñoz-Carrero, Pablo Serrano-Balazote","doi":"10.1055/s-0042-1757763","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>During the COVID-19 pandemic, several methodologies were designed for obtaining electronic health record (EHR)-derived datasets for research. These processes are often based on black boxes, on which clinical researchers are unaware of how the data were recorded, extracted, and transformed. In order to solve this, it is essential that extract, transform, and load (ETL) processes are based on transparent, homogeneous, and formal methodologies, making them understandable, reproducible, and auditable.</p><p><strong>Objectives: </strong>This study aims to design and implement a methodology, according with FAIR Principles, for building ETL processes (focused on data extraction, selection, and transformation) for EHR reuse in a transparent and flexible manner, applicable to any clinical condition and health care organization.</p><p><strong>Methods: </strong>The proposed methodology comprises four stages: (1) analysis of secondary use models and identification of data operations, based on internationally used clinical repositories, case report forms, and aggregated datasets; (2) modeling and formalization of data operations, through the paradigm of the Detailed Clinical Models; (3) agnostic development of data operations, selecting SQL and R as programming languages; and (4) automation of the ETL instantiation, building a formal configuration file with XML.</p><p><strong>Results: </strong>First, four international projects were analyzed to identify 17 operations, necessary to obtain datasets according to the specifications of these projects from the EHR. With this, each of the data operations was formalized, using the ISO 13606 reference model, specifying the valid data types as arguments, inputs and outputs, and their cardinality. Then, an agnostic catalog of data was developed through data-oriented programming languages previously selected. Finally, an automated ETL instantiation process was built from an ETL configuration file formally defined.</p><p><strong>Conclusions: </strong>This study has provided a transparent and flexible solution to the difficulty of making the processes for obtaining EHR-derived data for secondary use understandable, auditable, and reproducible. Moreover, the abstraction carried out in this study means that any previous EHR reuse methodology can incorporate these results into them.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":"61 S 02","pages":"e89-e102"},"PeriodicalIF":1.8000,"publicationDate":"2022-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/54/b2/10-1055-s-0042-1757763.PMC9788916.pdf","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0042-1757763","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 2
Abstract
Background: During the COVID-19 pandemic, several methodologies were designed for obtaining electronic health record (EHR)-derived datasets for research. These processes are often based on black boxes, on which clinical researchers are unaware of how the data were recorded, extracted, and transformed. In order to solve this, it is essential that extract, transform, and load (ETL) processes are based on transparent, homogeneous, and formal methodologies, making them understandable, reproducible, and auditable.
Objectives: This study aims to design and implement a methodology, according with FAIR Principles, for building ETL processes (focused on data extraction, selection, and transformation) for EHR reuse in a transparent and flexible manner, applicable to any clinical condition and health care organization.
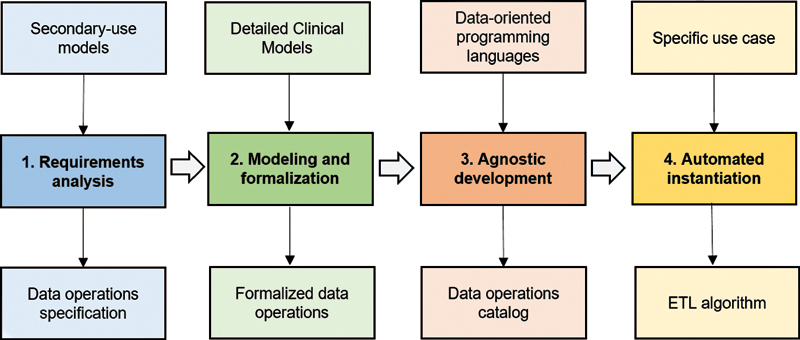
Methods: The proposed methodology comprises four stages: (1) analysis of secondary use models and identification of data operations, based on internationally used clinical repositories, case report forms, and aggregated datasets; (2) modeling and formalization of data operations, through the paradigm of the Detailed Clinical Models; (3) agnostic development of data operations, selecting SQL and R as programming languages; and (4) automation of the ETL instantiation, building a formal configuration file with XML.
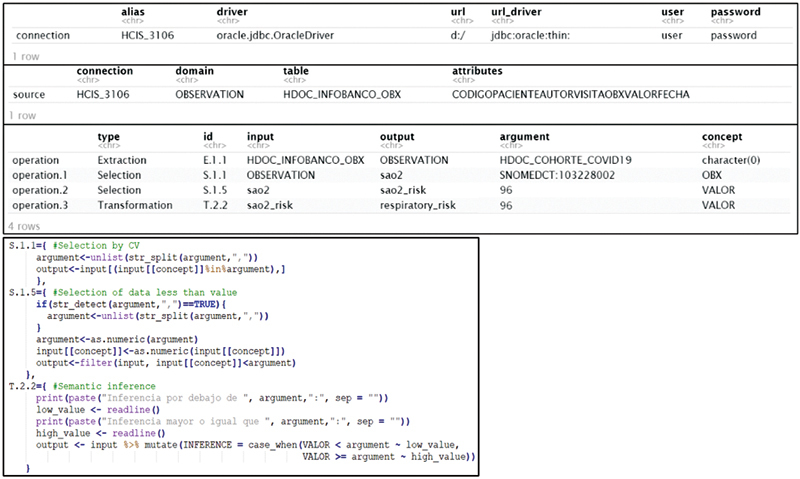
Results: First, four international projects were analyzed to identify 17 operations, necessary to obtain datasets according to the specifications of these projects from the EHR. With this, each of the data operations was formalized, using the ISO 13606 reference model, specifying the valid data types as arguments, inputs and outputs, and their cardinality. Then, an agnostic catalog of data was developed through data-oriented programming languages previously selected. Finally, an automated ETL instantiation process was built from an ETL configuration file formally defined.
Conclusions: This study has provided a transparent and flexible solution to the difficulty of making the processes for obtaining EHR-derived data for secondary use understandable, auditable, and reproducible. Moreover, the abstraction carried out in this study means that any previous EHR reuse methodology can incorporate these results into them.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


