Reihaneh Torkzadehmahani, Reza Nasirigerdeh, David B Blumenthal, Tim Kacprowski, Markus List, Julian Matschinske, Julian Spaeth, Nina Kerstin Wenke, Jan Baumbach
{"title":"Privacy-Preserving Artificial Intelligence Techniques in Biomedicine.","authors":"Reihaneh Torkzadehmahani, Reza Nasirigerdeh, David B Blumenthal, Tim Kacprowski, Markus List, Julian Matschinske, Julian Spaeth, Nina Kerstin Wenke, Jan Baumbach","doi":"10.1055/s-0041-1740630","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence (AI) has been successfully applied in numerous scientific domains. In biomedicine, AI has already shown tremendous potential, e.g., in the interpretation of next-generation sequencing data and in the design of clinical decision support systems.</p><p><strong>Objectives: </strong>However, training an AI model on sensitive data raises concerns about the privacy of individual participants. For example, summary statistics of a genome-wide association study can be used to determine the presence or absence of an individual in a given dataset. This considerable privacy risk has led to restrictions in accessing genomic and other biomedical data, which is detrimental for collaborative research and impedes scientific progress. Hence, there has been a substantial effort to develop AI methods that can learn from sensitive data while protecting individuals' privacy.</p><p><strong>Method: </strong>This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy and discusses their strengths, limitations, and open problems.</p><p><strong>Conclusion: </strong>As the most promising direction, we suggest combining federated machine learning as a more scalable approach with other additional privacy-preserving techniques. This would allow to merge the advantages to provide privacy guarantees in a distributed way for biomedical applications. Nonetheless, more research is necessary as hybrid approaches pose new challenges such as additional network or computation overhead.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":"61 S 01","pages":"e12-e27"},"PeriodicalIF":1.8000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/dd/7f/10-1055-s-0041-1740630.PMC9246509.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0041-1740630","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/21 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Artificial intelligence (AI) has been successfully applied in numerous scientific domains. In biomedicine, AI has already shown tremendous potential, e.g., in the interpretation of next-generation sequencing data and in the design of clinical decision support systems.
Objectives: However, training an AI model on sensitive data raises concerns about the privacy of individual participants. For example, summary statistics of a genome-wide association study can be used to determine the presence or absence of an individual in a given dataset. This considerable privacy risk has led to restrictions in accessing genomic and other biomedical data, which is detrimental for collaborative research and impedes scientific progress. Hence, there has been a substantial effort to develop AI methods that can learn from sensitive data while protecting individuals' privacy.
Method: This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy and discusses their strengths, limitations, and open problems.
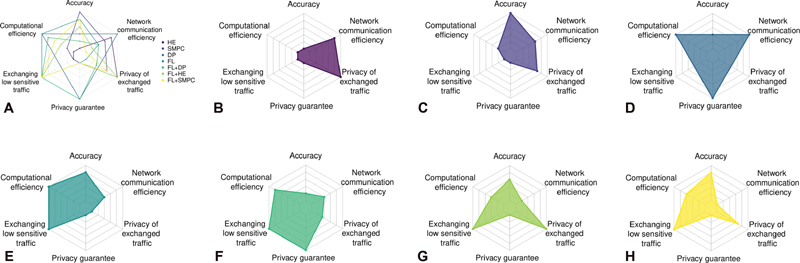
Conclusion: As the most promising direction, we suggest combining federated machine learning as a more scalable approach with other additional privacy-preserving techniques. This would allow to merge the advantages to provide privacy guarantees in a distributed way for biomedical applications. Nonetheless, more research is necessary as hybrid approaches pose new challenges such as additional network or computation overhead.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


