Yu-Ning Huang, Pooja Vinod Jaiswal, Anushka Rajesh, Anushka Yadav, Dottie Yu, Fangyun Liu, Grace Scheg, Emma Shih, Grigore Boldirev, Irina Nakashidze, Aditya Sarkar, Jay Himanshu Mehta, Ke Wang, Khooshbu Kantibhai Patel, Mustafa Ali Baig Mirza, Kunali Chetan Hapani, Qiushi Peng, Ram Ayyala, Ruiwei Guo, Shaunak Kapur, Tejasvene Ramesh, Dumitru Ciorbă, Viorel Munteanu, Viorel Bostan, Mihai Dimian, Malak S Abedalthagafi, Serghei Mangul
{"title":"The systematic assessment of completeness of public metadata accompanying omics studies in the Gene Expression Omnibus.","authors":"Yu-Ning Huang, Pooja Vinod Jaiswal, Anushka Rajesh, Anushka Yadav, Dottie Yu, Fangyun Liu, Grace Scheg, Emma Shih, Grigore Boldirev, Irina Nakashidze, Aditya Sarkar, Jay Himanshu Mehta, Ke Wang, Khooshbu Kantibhai Patel, Mustafa Ali Baig Mirza, Kunali Chetan Hapani, Qiushi Peng, Ram Ayyala, Ruiwei Guo, Shaunak Kapur, Tejasvene Ramesh, Dumitru Ciorbă, Viorel Munteanu, Viorel Bostan, Mihai Dimian, Malak S Abedalthagafi, Serghei Mangul","doi":"10.1101/2021.11.22.469640","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advances in high-throughput sequencing technologies have made it possible to collect and share a massive amount of omics data, along with its associated metadata. Enhancing metadata availability is critical to ensure data reusability and reproducibility and to facilitate novel biomedical discoveries through effective data reuse. Yet, incomplete metadata accompanying public omics data may hinder reproducibility and reusability by reducing sample interpretability and limiting secondary analyses. In this study, we performed a comprehensive assessment of metadata completeness shared in both scientific publications and/or public repositories by analyzing over 253 studies encompassing over 164 thousands samples, including both human and non-human mammalian studies. We observed that studies often omit over a quarter of important phenotypes, with an average of only 74.8% of them shared either in the text of publication or the corresponding repository. Notably, public repositories alone contained 62% of the metadata, surpassing the textual content of publications by 3.5%. Only 11.5% of studies completely shared all phenotypes, while 37.9% shared less than 40% of the phenotypes. Studies involving non-human samples were more likely to share metadata than studies involving human samples. We observed similar results on the extended dataset spanning 2.1 million samples across over 61,000 studies from the Gene Expression Omnibus repository. The limited availability of metadata reported in our study emphasizes the necessity for improved metadata sharing practices and standardized reporting. Finally, we discuss the numerous benefits of improving the availability and quality of metadata to the scientific community and beyond, supporting data-driven decision-making and policy development in the field of biomedical research. This work provides a scalable framework for evaluating metadata availability and may help guide future policy and infrastructure development.</p>","PeriodicalId":72407,"journal":{"name":"bioRxiv : the preprint server for biology","volume":"3 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-07-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12265520/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"bioRxiv : the preprint server for biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2021.11.22.469640","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
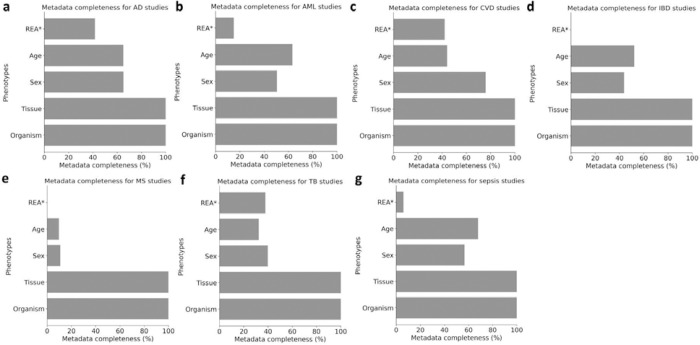
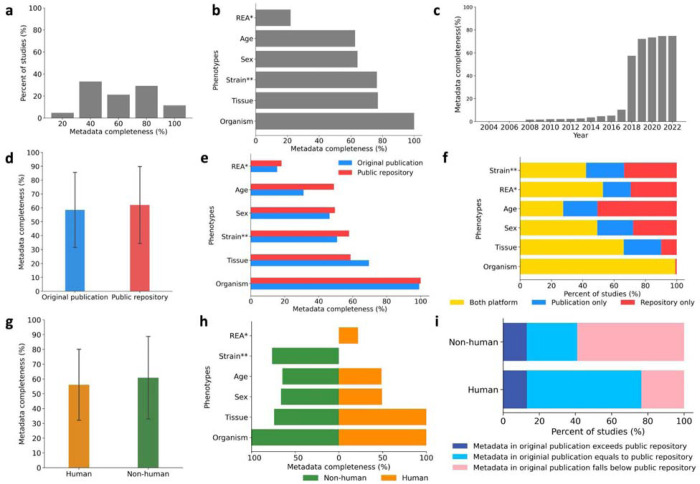
Recent advances in high-throughput sequencing technologies have made it possible to collect and share a massive amount of omics data, along with its associated metadata. Enhancing metadata availability is critical to ensure data reusability and reproducibility and to facilitate novel biomedical discoveries through effective data reuse. Yet, incomplete metadata accompanying public omics data may hinder reproducibility and reusability by reducing sample interpretability and limiting secondary analyses. In this study, we performed a comprehensive assessment of metadata completeness shared in both scientific publications and/or public repositories by analyzing over 253 studies encompassing over 164 thousands samples, including both human and non-human mammalian studies. We observed that studies often omit over a quarter of important phenotypes, with an average of only 74.8% of them shared either in the text of publication or the corresponding repository. Notably, public repositories alone contained 62% of the metadata, surpassing the textual content of publications by 3.5%. Only 11.5% of studies completely shared all phenotypes, while 37.9% shared less than 40% of the phenotypes. Studies involving non-human samples were more likely to share metadata than studies involving human samples. We observed similar results on the extended dataset spanning 2.1 million samples across over 61,000 studies from the Gene Expression Omnibus repository. The limited availability of metadata reported in our study emphasizes the necessity for improved metadata sharing practices and standardized reporting. Finally, we discuss the numerous benefits of improving the availability and quality of metadata to the scientific community and beyond, supporting data-driven decision-making and policy development in the field of biomedical research. This work provides a scalable framework for evaluating metadata availability and may help guide future policy and infrastructure development.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


