Soohyun Kim, Jongbeom Baek, Jihye Park, Eunjae Ha, Homin Jung, Taeyoung Lee, Seungryong Kim
{"title":"InstaFormer++: Multi-Domain Instance-Aware Image-to-Image Translation with Transformer","authors":"Soohyun Kim, Jongbeom Baek, Jihye Park, Eunjae Ha, Homin Jung, Taeyoung Lee, Seungryong Kim","doi":"10.1007/s11263-023-01866-y","DOIUrl":null,"url":null,"abstract":"<p>We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as visual tokens, our model discovers global consensus of content features by considering context information through self-attention module of Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. Although competitive performance can be attained by InstaFormer, it may face some limitations, i.e., limited scalability in handling multiple domains, and reliance on domain annotations. To overcome this, we propose InstaFormer++ as an extension of Instaformer, which enables multi-domain translation in instance-aware image translation for the first time. We propose to obtain pseudo domain label by leveraging a list of candidate domain labels in a text format and pretrained vision-language model. We conduct experiments to demonstrate the effectiveness of our methods over the latest methods and provide extensive ablation studies.\n</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"31 20","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-10-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01866-y","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
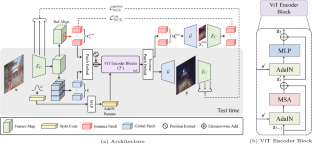
We present a novel Transformer-based network architecture for instance-aware image-to-image translation, dubbed InstaFormer, to effectively integrate global- and instance-level information. By considering extracted content features from an image as visual tokens, our model discovers global consensus of content features by considering context information through self-attention module of Transformers. By augmenting such tokens with an instance-level feature extracted from the content feature with respect to bounding box information, our framework is capable of learning an interaction between object instances and the global image, thus boosting the instance-awareness. We replace layer normalization (LayerNorm) in standard Transformers with adaptive instance normalization (AdaIN) to enable a multi-modal translation with style codes. In addition, to improve the instance-awareness and translation quality at object regions, we present an instance-level content contrastive loss defined between input and translated image. Although competitive performance can be attained by InstaFormer, it may face some limitations, i.e., limited scalability in handling multiple domains, and reliance on domain annotations. To overcome this, we propose InstaFormer++ as an extension of Instaformer, which enables multi-domain translation in instance-aware image translation for the first time. We propose to obtain pseudo domain label by leveraging a list of candidate domain labels in a text format and pretrained vision-language model. We conduct experiments to demonstrate the effectiveness of our methods over the latest methods and provide extensive ablation studies.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


