Tse Chian Chen, Evan Multala, Patrick Kearns, Johnny Delashaw, Aaron Dumont, Demetrius Maraganore, Arthur Wang
{"title":"Assessment of ChatGPT's performance on neurology written board examination questions.","authors":"Tse Chian Chen, Evan Multala, Patrick Kearns, Johnny Delashaw, Aaron Dumont, Demetrius Maraganore, Arthur Wang","doi":"10.1136/bmjno-2023-000530","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and objectives: </strong>ChatGPT has shown promise in healthcare. To assess the utility of this novel tool in healthcare education, we evaluated ChatGPT's performance in answering neurology board exam questions.</p><p><strong>Methods: </strong>Neurology board-style examination questions were accessed from BoardVitals, a commercial neurology question bank. ChatGPT was provided a full question prompt and multiple answer choices. First attempts and additional attempts up to three tries were given to ChatGPT to select the correct answer. A total of 560 questions (14 blocks of 40 questions) were used, although any image-based questions were disregarded due to ChatGPT's inability to process visual input. The artificial intelligence (AI) answers were then compared with human user data provided by the question bank to gauge its performance.</p><p><strong>Results: </strong>Out of 509 eligible questions over 14 question blocks, ChatGPT correctly answered 335 questions (65.8%) on the first attempt/iteration and 383 (75.3%) over three attempts/iterations, scoring at approximately the 26th and 50th percentiles, respectively. The highest performing subjects were pain (100%), epilepsy & seizures (85%) and genetic (82%) while the lowest performing subjects were imaging/diagnostic studies (27%), critical care (41%) and cranial nerves (48%).</p><p><strong>Discussion: </strong>This study found that ChatGPT performed similarly to its human counterparts. The accuracy of the AI increased with multiple attempts and performance fell within the expected range of neurology resident learners. This study demonstrates ChatGPT's potential in processing specialised medical information. Future studies would better define the scope to which AI would be able to integrate into medical decision making.</p>","PeriodicalId":52754,"journal":{"name":"BMJ Neurology Open","volume":null,"pages":null},"PeriodicalIF":2.1000,"publicationDate":"2023-11-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10626870/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Neurology Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjno-2023-000530","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"CLINICAL NEUROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background and objectives: ChatGPT has shown promise in healthcare. To assess the utility of this novel tool in healthcare education, we evaluated ChatGPT's performance in answering neurology board exam questions.
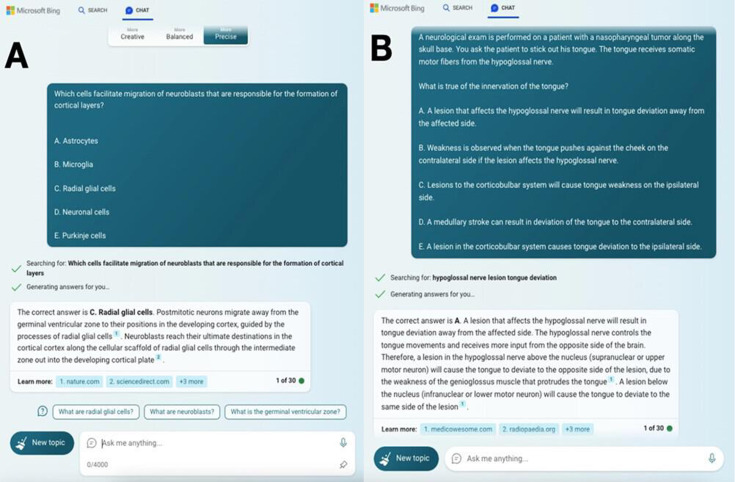
Methods: Neurology board-style examination questions were accessed from BoardVitals, a commercial neurology question bank. ChatGPT was provided a full question prompt and multiple answer choices. First attempts and additional attempts up to three tries were given to ChatGPT to select the correct answer. A total of 560 questions (14 blocks of 40 questions) were used, although any image-based questions were disregarded due to ChatGPT's inability to process visual input. The artificial intelligence (AI) answers were then compared with human user data provided by the question bank to gauge its performance.
Results: Out of 509 eligible questions over 14 question blocks, ChatGPT correctly answered 335 questions (65.8%) on the first attempt/iteration and 383 (75.3%) over three attempts/iterations, scoring at approximately the 26th and 50th percentiles, respectively. The highest performing subjects were pain (100%), epilepsy & seizures (85%) and genetic (82%) while the lowest performing subjects were imaging/diagnostic studies (27%), critical care (41%) and cranial nerves (48%).
Discussion: This study found that ChatGPT performed similarly to its human counterparts. The accuracy of the AI increased with multiple attempts and performance fell within the expected range of neurology resident learners. This study demonstrates ChatGPT's potential in processing specialised medical information. Future studies would better define the scope to which AI would be able to integrate into medical decision making.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


