An effective fault tolerance aware scheduling using hybrid horse herd optimisation-reptile search optimisation approach for a cloud computing environment
IF 1.3 Q4 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
{"title":"An effective fault tolerance aware scheduling using hybrid horse herd optimisation-reptile search optimisation approach for a cloud computing environment","authors":"Manoj Kumar Malik, Hitesh Joshi, Abhishek Swaroop","doi":"10.1049/ccs2.12094","DOIUrl":null,"url":null,"abstract":"<p>IT services can be requested via cloud computing, a model based on services as well as the Internet. It includes all computer systems resources from hardware components to software platforms and software applications in a distributed environment. Scheduling is a key step in processing tasks using remote resources. Serious issues have been brought forward, including the ineffective use of resources and task execution failure. The concurrent provision of fault tolerance and resource optimisation is achallenging task. In the context of cloud computing, this research offers a brand-new job scheduling and fault-tolerant system. Tasks submitted by users are taken as an input for the proposed method. Several virtual machines (VM) are initially arranged for scheduling work and execution process. Initially, Horse Herd Optimisation is employed here to allocate the job based on key factors such as deadline and user budget. Once the jobs are assigned to each VM, then each job's deadline is confirmed and transferred to VM which has sufficient capacity. Here, the Reptile Search Optimisation technique is applied to identify the VM error. Any VM that does not have enough capacity is the one that has a problem. When a fault is found, a fault-tolerant process is instantly started. A replication-based fault-tolerant mechanism is used in this manuscript. The proposed approach is tested with several metrics which attains better performance like 80 s response time, turnaround time of 32 s, 17% resource utilisation and a success rate of 92%. Thus the designed model is the best choice for fault-tolerant aware task scheduling.</p>","PeriodicalId":33652,"journal":{"name":"Cognitive Computation and Systems","volume":"5 3","pages":"231-242"},"PeriodicalIF":1.3000,"publicationDate":"2023-10-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/ccs2.12094","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation and Systems","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/ccs2.12094","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
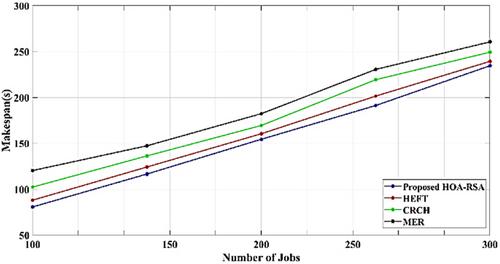
IT services can be requested via cloud computing, a model based on services as well as the Internet. It includes all computer systems resources from hardware components to software platforms and software applications in a distributed environment. Scheduling is a key step in processing tasks using remote resources. Serious issues have been brought forward, including the ineffective use of resources and task execution failure. The concurrent provision of fault tolerance and resource optimisation is achallenging task. In the context of cloud computing, this research offers a brand-new job scheduling and fault-tolerant system. Tasks submitted by users are taken as an input for the proposed method. Several virtual machines (VM) are initially arranged for scheduling work and execution process. Initially, Horse Herd Optimisation is employed here to allocate the job based on key factors such as deadline and user budget. Once the jobs are assigned to each VM, then each job's deadline is confirmed and transferred to VM which has sufficient capacity. Here, the Reptile Search Optimisation technique is applied to identify the VM error. Any VM that does not have enough capacity is the one that has a problem. When a fault is found, a fault-tolerant process is instantly started. A replication-based fault-tolerant mechanism is used in this manuscript. The proposed approach is tested with several metrics which attains better performance like 80 s response time, turnaround time of 32 s, 17% resource utilisation and a success rate of 92%. Thus the designed model is the best choice for fault-tolerant aware task scheduling.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


