Orhun Aydin, Mark V. Janikas, Renato Martins Assunção, Ting-Hwan Lee
{"title":"Probabilistic Regionalization via Evidence Accumulation with Random Spanning Trees as Weak Spatial Representations","authors":"Orhun Aydin, Mark V. Janikas, Renato Martins Assunção, Ting-Hwan Lee","doi":"10.1111/gean.12376","DOIUrl":null,"url":null,"abstract":"<p>Spatial clusters contain biases and artifacts, whether they are defined via statistical algorithms or via expert judgment. Graph-based partitioning of spatial data and associated heuristics gained popularity due to their scalability but can define suboptimal regions due to algorithmic biases such as chaining. Despite the broad literature on deterministic regionalization methods, approaches that quantify regionalization probability are sparse. In this article, we propose a local method to quantify regionalization probabilities for regions defined via graph-based cuts and expert-defined regions. We conceptualize spatial regions as consisting of two types of spatial elements: core and swing. We define three distinct types of regionalization biases that occur in graph-based methods and showcase the use of the proposed method to capture these types of biases. Additionally, we propose an efficient solution to the probabilistic graph-based regionalization problem via performing optimal tree cuts along random spanning trees within an evidence accumulation framework. We perform statistical tests on synthetic data to assess resulting probability maps for varying distinctness of underlying regions and regionalization parameters. Lastly, we showcase the application of our method to define probabilistic ecoregions using climatic and remotely sensed vegetation indicators and apply our method to assign probabilities to the expert-defined Bailey's ecoregions.</p>","PeriodicalId":12533,"journal":{"name":"Geographical Analysis","volume":"56 2","pages":"328-357"},"PeriodicalIF":4.3000,"publicationDate":"2023-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/gean.12376","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Geographical Analysis","FirstCategoryId":"89","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/gean.12376","RegionNum":3,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GEOGRAPHY","Score":null,"Total":0}
引用次数: 0
Abstract
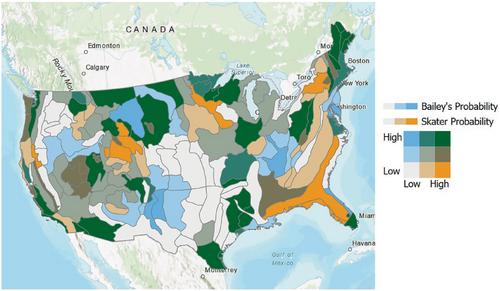
Spatial clusters contain biases and artifacts, whether they are defined via statistical algorithms or via expert judgment. Graph-based partitioning of spatial data and associated heuristics gained popularity due to their scalability but can define suboptimal regions due to algorithmic biases such as chaining. Despite the broad literature on deterministic regionalization methods, approaches that quantify regionalization probability are sparse. In this article, we propose a local method to quantify regionalization probabilities for regions defined via graph-based cuts and expert-defined regions. We conceptualize spatial regions as consisting of two types of spatial elements: core and swing. We define three distinct types of regionalization biases that occur in graph-based methods and showcase the use of the proposed method to capture these types of biases. Additionally, we propose an efficient solution to the probabilistic graph-based regionalization problem via performing optimal tree cuts along random spanning trees within an evidence accumulation framework. We perform statistical tests on synthetic data to assess resulting probability maps for varying distinctness of underlying regions and regionalization parameters. Lastly, we showcase the application of our method to define probabilistic ecoregions using climatic and remotely sensed vegetation indicators and apply our method to assign probabilities to the expert-defined Bailey's ecoregions.
期刊介绍:
First in its specialty area and one of the most frequently cited publications in geography, Geographical Analysis has, since 1969, presented significant advances in geographical theory, model building, and quantitative methods to geographers and scholars in a wide spectrum of related fields. Traditionally, mathematical and nonmathematical articulations of geographical theory, and statements and discussions of the analytic paradigm are published in the journal. Spatial data analyses and spatial econometrics and statistics are strongly represented.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


