Yongqin Ye, Shuvam Sarkar, Anand Bhaskar, Brian Tomlinson, Olivia Monteiro
{"title":"Using ChatGPT in a clinical setting: A case report","authors":"Yongqin Ye, Shuvam Sarkar, Anand Bhaskar, Brian Tomlinson, Olivia Monteiro","doi":"10.1002/mef2.51","DOIUrl":null,"url":null,"abstract":"<p>Large language models (LLMs) are rapidly becoming an important foundation model that has infiltrated our daily lives in many ways. The release of GPT-3 and GPT-4, a LLM that is capable of natural language processing (NLP) that has been trained on terabytes of text data through transfer learning to apply knowledge gained from a previous task to solve a different but related problem, immediately captured the attention of the medical field to investigate how LLMs can be used to process and interpret electronic health records and to streamline clinical writing.<span><sup>1</sup></span> NLP models have traditionally been used mainly as diagnostic aids in healthcare. Its use generally requires supervised learning on manually labeled and training datasets with a huge involvement of time from healthcare professionals.<span><sup>2</sup></span> NLP models often lack precision, accuracy and mostly only accessible by the developers. Recent LLMs with their transformer and reinforcement learning with human feedback, have enabled better precision in text generation. The advancement of GPT-3 (Generative Pre-Trained Transformer, commonly known as ChatGPT) demonstrated that LLMs can rapidly adapt to new tasks resulting in better generalization. Also, ChatGPT has a simple interface, which has enabled broad adoption and use. Having such a versatile and user-friendly tool at our fingertips means that we can adapt to use LLMs for basic tasks such as generating clinical reports, providing clinical support, or to synthesize patient data from multiple sources.</p><p>We have used this case report as an opportunity to demonstrate the practicality of ChatGPT in basic writing tasks in a clinical context. This case report is obtained from two teaching videos uploaded by TTMedcastTraining Texas Tech University on YouTube. The two videos are of a patient called Jonathan who presented with bilateral knee pain with a history of sickle cell disease. One video is the bedside presentation of the patient by a medical intern, another is a group discussion of treatment plans for this patient. Since GPT-3 can only deal with text input, we have downloaded the transcript from each video. The transcripts sometimes contain people talking at the same time, filler words, mispronounced words, or incomplete sentences. Unaltered transcripts were submitted to ChatGPT separately for interpretation.</p><p>The workflow of using ChatGPT to generate the case report is summarized in Figure 1. We fed the transcript of Video 1 into ChatGPT and asked it to write a case report from it (Case Report 1). Then, we used the transcript of Video 2 to create Case Report 2. ChatGPT was asked to combine the two reports without summarizing and offer a diagnosis and a treatment plan. We also asked ChatGPT to write the final case report in the style for the New England Journal of Medicine. This process took around 1.5 h, including time the authors spent watching the videos. The full case report is found in Supporting Information, ChatGPT's Case Report.</p><p>The first author, an attending physician in pediatric surgery, was also asked to study the videos and write a case report based on the two videos. Due to a heavy workload and varied schedule from his work, it took several attempts and in total roughly 4 h to complete. This report is found in Supporting Information, Physician's Case Report. He was also asked if he agreed with the diagnosis and treatment plan provided by ChatGPT. After careful research on sickle cell disease and its presentation, the first author agreed with the diagnosis and treatment plans.</p><p>To compare the quality of writing, we have asked three physicians to rate the two case reports according to a modified version of The Joanna Briggs Institute Critical Appraisal Checklist for Case Reports.<span><sup>3</sup></span> All three physicians gave the two reports similar scores of 5.7/8 and 6/8 for ChatGPT's and physician's report respectively. The most common comment regarding ChatGPT's report is the lack of the patient's past medical history while this information is more evident in the physician's report. Detailed comments are found in Supporting Information.</p><p>This study is a good example of how ChatGPT can be used effectively to perform simple writing tasks in a clinical setting when clinicians record their cases to write up later and how easy it is to use ChatGPT to synthesize data from multiple sources and to provide medical support. However, before ChatGPT can be used in day-to-day practice, several important points need to be raised. ChatGPT requires very detailed and specific information to write the final case report (the chat history detailing the prompts and the separate case reports generated is available in Supplementary Materials). Although the first report was not perfect, it is possible to refine the report by requesting ChatGPT to incorporate additional information. With practice, users will be familiarized with prompt strategies that will generate the desired outputs. In this case report, our prompts were clear and simple. We specified that the original text was a “transcript from a video” so that the format of the text input was understood. We employed strong and meaningful prompts such as “write,” “incorporate” and “combine” and qualified our request to “not summarize” the information given. In addition, we wanted to generate a case report in a format that most clinicians are familiar with reading. To this end, we prompted with the specific output format of “New England Journal of Medicine.”</p><p>One important point to highlight is that ChatGPT can be used to interpret incomplete medical data by offering diagnostic assessments and treatment plans based on medical history and patient symptoms. We believe that ChatGPT will be a useful assistant that can be used to complete time-consuming writing tasks, even when clinical data was partially missing. It is important to note that ChatGPT can provide ideas, but it cannot replace a clinician's knowledge. In-depth knowledge of their cases and the diseases being treated is absolutely necessary to ensure credibility of generated text and to avoid misinterpretation from the LLM. Clinicians must dedicate time to fact check generated reports soon after attending a case to avoid confusing generated material with actual medical records.<span><sup>4</sup></span> It remains the sole responsibility of the attending clinician to ensure patient data accuracy and privacy, and that they make the final diagnostic and treatment decisions to avoid any legal and ethical issues that may arise from incorrectly LLM-generated patient data.<span><sup>5</sup></span></p><p>With the advancement of fine-tuned medical LLMs such as GatorTron (a clinical LLM that is trained on deidentified clinical text to process and interpret electronic health records) and Google's Med-PaLM 2 (LLM that is billed to more accurately and safely answer medical questions), we can expect to see much more AI-generated text in every area of medicine. We must, however, remember that medicine is an interpersonal process, and the interaction and communication between doctor and patient remains irreplaceable. We can use LLMs to enhance the ability of practitioners to improve accuracy and precision whilst empowering patients with greater autonomy, but we must be mindful of ethical considerations of the integration of LLMs in medical practice.</p><p>In conclusion, ChatGPT has the potential to be a valuable tool for clinicians in generating case reports in a timely manner. However, its use requires practice and willingness to dedicate time to verify the accuracy of generated data using a clinician's expertise and knowledge.</p><p><b>Yongqin Ye</b>: Data curation (equal); formal analysis (equal); methodology (equal); validation (equal); writing—review and editing (equal). <b>Shuvam Sarkar</b>: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). <b>Anand Bhaskar</b>: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). <b>Brian Tomlinson</b>: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). <b>Olivia Monteiro</b>: Conceptualization (equal); data curation (equal); formal analysis (equal); methodology (equal); project administration (equal); resources (equal); software (equal); supervision (equal); validation (equal); writing—original draft (equal); writing—review and editing (equal). All authors have read and approved the final manuscript.</p><p>The authors declare no conflicts of interest.</p><p>Not applicable.</p>","PeriodicalId":74135,"journal":{"name":"MedComm - Future medicine","volume":"2 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-06-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/mef2.51","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"MedComm - Future medicine","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/mef2.51","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 1
Abstract
Large language models (LLMs) are rapidly becoming an important foundation model that has infiltrated our daily lives in many ways. The release of GPT-3 and GPT-4, a LLM that is capable of natural language processing (NLP) that has been trained on terabytes of text data through transfer learning to apply knowledge gained from a previous task to solve a different but related problem, immediately captured the attention of the medical field to investigate how LLMs can be used to process and interpret electronic health records and to streamline clinical writing.1 NLP models have traditionally been used mainly as diagnostic aids in healthcare. Its use generally requires supervised learning on manually labeled and training datasets with a huge involvement of time from healthcare professionals.2 NLP models often lack precision, accuracy and mostly only accessible by the developers. Recent LLMs with their transformer and reinforcement learning with human feedback, have enabled better precision in text generation. The advancement of GPT-3 (Generative Pre-Trained Transformer, commonly known as ChatGPT) demonstrated that LLMs can rapidly adapt to new tasks resulting in better generalization. Also, ChatGPT has a simple interface, which has enabled broad adoption and use. Having such a versatile and user-friendly tool at our fingertips means that we can adapt to use LLMs for basic tasks such as generating clinical reports, providing clinical support, or to synthesize patient data from multiple sources.
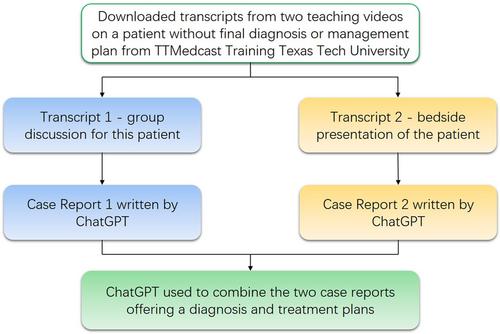
We have used this case report as an opportunity to demonstrate the practicality of ChatGPT in basic writing tasks in a clinical context. This case report is obtained from two teaching videos uploaded by TTMedcastTraining Texas Tech University on YouTube. The two videos are of a patient called Jonathan who presented with bilateral knee pain with a history of sickle cell disease. One video is the bedside presentation of the patient by a medical intern, another is a group discussion of treatment plans for this patient. Since GPT-3 can only deal with text input, we have downloaded the transcript from each video. The transcripts sometimes contain people talking at the same time, filler words, mispronounced words, or incomplete sentences. Unaltered transcripts were submitted to ChatGPT separately for interpretation.
The workflow of using ChatGPT to generate the case report is summarized in Figure 1. We fed the transcript of Video 1 into ChatGPT and asked it to write a case report from it (Case Report 1). Then, we used the transcript of Video 2 to create Case Report 2. ChatGPT was asked to combine the two reports without summarizing and offer a diagnosis and a treatment plan. We also asked ChatGPT to write the final case report in the style for the New England Journal of Medicine. This process took around 1.5 h, including time the authors spent watching the videos. The full case report is found in Supporting Information, ChatGPT's Case Report.
The first author, an attending physician in pediatric surgery, was also asked to study the videos and write a case report based on the two videos. Due to a heavy workload and varied schedule from his work, it took several attempts and in total roughly 4 h to complete. This report is found in Supporting Information, Physician's Case Report. He was also asked if he agreed with the diagnosis and treatment plan provided by ChatGPT. After careful research on sickle cell disease and its presentation, the first author agreed with the diagnosis and treatment plans.
To compare the quality of writing, we have asked three physicians to rate the two case reports according to a modified version of The Joanna Briggs Institute Critical Appraisal Checklist for Case Reports.3 All three physicians gave the two reports similar scores of 5.7/8 and 6/8 for ChatGPT's and physician's report respectively. The most common comment regarding ChatGPT's report is the lack of the patient's past medical history while this information is more evident in the physician's report. Detailed comments are found in Supporting Information.
This study is a good example of how ChatGPT can be used effectively to perform simple writing tasks in a clinical setting when clinicians record their cases to write up later and how easy it is to use ChatGPT to synthesize data from multiple sources and to provide medical support. However, before ChatGPT can be used in day-to-day practice, several important points need to be raised. ChatGPT requires very detailed and specific information to write the final case report (the chat history detailing the prompts and the separate case reports generated is available in Supplementary Materials). Although the first report was not perfect, it is possible to refine the report by requesting ChatGPT to incorporate additional information. With practice, users will be familiarized with prompt strategies that will generate the desired outputs. In this case report, our prompts were clear and simple. We specified that the original text was a “transcript from a video” so that the format of the text input was understood. We employed strong and meaningful prompts such as “write,” “incorporate” and “combine” and qualified our request to “not summarize” the information given. In addition, we wanted to generate a case report in a format that most clinicians are familiar with reading. To this end, we prompted with the specific output format of “New England Journal of Medicine.”
One important point to highlight is that ChatGPT can be used to interpret incomplete medical data by offering diagnostic assessments and treatment plans based on medical history and patient symptoms. We believe that ChatGPT will be a useful assistant that can be used to complete time-consuming writing tasks, even when clinical data was partially missing. It is important to note that ChatGPT can provide ideas, but it cannot replace a clinician's knowledge. In-depth knowledge of their cases and the diseases being treated is absolutely necessary to ensure credibility of generated text and to avoid misinterpretation from the LLM. Clinicians must dedicate time to fact check generated reports soon after attending a case to avoid confusing generated material with actual medical records.4 It remains the sole responsibility of the attending clinician to ensure patient data accuracy and privacy, and that they make the final diagnostic and treatment decisions to avoid any legal and ethical issues that may arise from incorrectly LLM-generated patient data.5
With the advancement of fine-tuned medical LLMs such as GatorTron (a clinical LLM that is trained on deidentified clinical text to process and interpret electronic health records) and Google's Med-PaLM 2 (LLM that is billed to more accurately and safely answer medical questions), we can expect to see much more AI-generated text in every area of medicine. We must, however, remember that medicine is an interpersonal process, and the interaction and communication between doctor and patient remains irreplaceable. We can use LLMs to enhance the ability of practitioners to improve accuracy and precision whilst empowering patients with greater autonomy, but we must be mindful of ethical considerations of the integration of LLMs in medical practice.
In conclusion, ChatGPT has the potential to be a valuable tool for clinicians in generating case reports in a timely manner. However, its use requires practice and willingness to dedicate time to verify the accuracy of generated data using a clinician's expertise and knowledge.
Yongqin Ye: Data curation (equal); formal analysis (equal); methodology (equal); validation (equal); writing—review and editing (equal). Shuvam Sarkar: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). Anand Bhaskar: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). Brian Tomlinson: Data curation (equal); formal analysis (equal); validation (equal); writing—review and editing (equal). Olivia Monteiro: Conceptualization (equal); data curation (equal); formal analysis (equal); methodology (equal); project administration (equal); resources (equal); software (equal); supervision (equal); validation (equal); writing—original draft (equal); writing—review and editing (equal). All authors have read and approved the final manuscript.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


