{"title":"On the parallelization of stellar evolution codes","authors":"David Martin, Jordi José, Richard Longland","doi":"10.1186/s40668-018-0025-5","DOIUrl":null,"url":null,"abstract":"<p>Multidimensional nucleosynthesis studies with hundreds of nuclei linked through thousands of nuclear processes are still computationally prohibitive. To date, most nucleosynthesis studies rely either on hydrostatic/hydrodynamic simulations in spherical symmetry, or on post-processing simulations using temperature and density versus time profiles directly linked to huge nuclear reaction networks.</p><p>Parallel computing has been regarded as the main permitting factor of computationally intensive simulations. This paper explores the different pros and cons in the parallelization of stellar codes, providing recommendations on when and how parallelization may help in improving the performance of a code for astrophysical applications.</p><p>We report on different parallelization strategies succesfully applied to the spherically symmetric, Lagrangian, implicit hydrodynamic code <span>SHIVA</span>, extensively used in the modeling of classical novae and type I X-ray bursts.</p><p>When only matrix build-up and inversion processes in the nucleosynthesis subroutines are parallelized (a suitable approach for post-processing calculations), the huge amount of time spent on communications between cores, together with the small problem size (limited by the number of isotopes of the nuclear network), result in a much worse performance of the parallel application compared to the 1-core, sequential version of the code. Parallelization of the matrix build-up and inversion processes in the nucleosynthesis subroutines is not recommended unless the number of isotopes adopted largely exceeds 10,000.</p><p>In sharp contrast, speed-up factors of 26 and 35 have been obtained with a parallelized version of <span>SHIVA</span>, in a 200-shell simulation of a type I X-ray burst carried out with two nuclear reaction networks: a reduced one, consisting of 324 isotopes and 1392 reactions, and a more extended network with 606 nuclides and 3551 nuclear interactions. Maximum speed-ups of ~41 (324-isotope network) and ~85 (606-isotope network), are also predicted for 200 cores, stressing that the number of shells of the computational domain constitutes an effective upper limit for the maximum number of cores that could be used in a parallel application.</p>","PeriodicalId":523,"journal":{"name":"Computational Astrophysics and Cosmology","volume":"5 1","pages":""},"PeriodicalIF":16.2810,"publicationDate":"2018-11-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s40668-018-0025-5","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Astrophysics and Cosmology","FirstCategoryId":"4","ListUrlMain":"https://link.springer.com/article/10.1186/s40668-018-0025-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
Multidimensional nucleosynthesis studies with hundreds of nuclei linked through thousands of nuclear processes are still computationally prohibitive. To date, most nucleosynthesis studies rely either on hydrostatic/hydrodynamic simulations in spherical symmetry, or on post-processing simulations using temperature and density versus time profiles directly linked to huge nuclear reaction networks.
Parallel computing has been regarded as the main permitting factor of computationally intensive simulations. This paper explores the different pros and cons in the parallelization of stellar codes, providing recommendations on when and how parallelization may help in improving the performance of a code for astrophysical applications.
We report on different parallelization strategies succesfully applied to the spherically symmetric, Lagrangian, implicit hydrodynamic code SHIVA, extensively used in the modeling of classical novae and type I X-ray bursts.
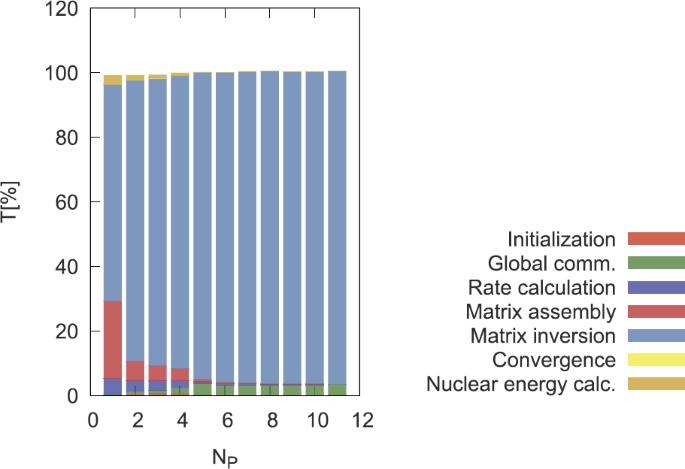
When only matrix build-up and inversion processes in the nucleosynthesis subroutines are parallelized (a suitable approach for post-processing calculations), the huge amount of time spent on communications between cores, together with the small problem size (limited by the number of isotopes of the nuclear network), result in a much worse performance of the parallel application compared to the 1-core, sequential version of the code. Parallelization of the matrix build-up and inversion processes in the nucleosynthesis subroutines is not recommended unless the number of isotopes adopted largely exceeds 10,000.
In sharp contrast, speed-up factors of 26 and 35 have been obtained with a parallelized version of SHIVA, in a 200-shell simulation of a type I X-ray burst carried out with two nuclear reaction networks: a reduced one, consisting of 324 isotopes and 1392 reactions, and a more extended network with 606 nuclides and 3551 nuclear interactions. Maximum speed-ups of ~41 (324-isotope network) and ~85 (606-isotope network), are also predicted for 200 cores, stressing that the number of shells of the computational domain constitutes an effective upper limit for the maximum number of cores that could be used in a parallel application.
期刊介绍:
Computational Astrophysics and Cosmology (CompAC) is now closed and no longer accepting submissions. However, we would like to assure you that Springer will maintain an archive of all articles published in CompAC, ensuring their accessibility through SpringerLink's comprehensive search functionality.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


