Timothy E.H. Allen , Alistair M. Middleton , Jonathan M. Goodman , Paul J. Russell , Predrag Kukic , Steve Gutsell
{"title":"Towards quantifying the uncertainty in in silico predictions using Bayesian learning","authors":"Timothy E.H. Allen , Alistair M. Middleton , Jonathan M. Goodman , Paul J. Russell , Predrag Kukic , Steve Gutsell","doi":"10.1016/j.comtox.2022.100228","DOIUrl":null,"url":null,"abstract":"<div><p>Next-generation risk assessment (NGRA) involves the combination of <em>in vitro</em> and <em>in silico</em> models for more human-relevant, ethical, and sustainable human chemical safety assessment. NGRA requires a quantitative mechanistic understanding of the effects of chemicals across human biology (be they molecular, cellular, organ-level or higher) coupled with a quantitative understanding of the uncertainty in any experimentally measured or predicted values. These values with their uncertainties can then be considered as a probability distribution, which can then be compared to exposure estimates to establish the presence or absence of a margin of safety. We have constructed Bayesian learning neural networks to provide such quantitative predictions and uncertainties for 20 pharmacologically important human molecular initiating events. These models produce high quality quantitative estimates (p(IC50), p(EC50), p(Ki), p(Kd)) of biochemical activity at a molecular initiating event (MIE) with average mean absolute errors (in Log units) of 0.625 ± 0.048 in test data and 0.941 ± 0.215 in external validation data. The key advantage of these models is their ability to also produce standard deviations and credible intervals (CIs) to quantify the uncertainty in these predictions, which we show to be able to distinguish between molecules close to the training data in chemical structure, those less similar to the training data, and decoy compounds drawn from the wider ChEMBL database. These uncertainty values mean that when a prediction is made a user can understand the certainty of the prediction, similar to a quantitative applicability domain, aiding prediction usefulness in NGRA. The ability for <em>in silico</em> methods to produce quantitative predictions with these kinds of probability distributions will be vital to their further use in NGRA, and here clear first steps have been taken.</p></div>","PeriodicalId":72666,"journal":{"name":"","volume":"23 ","pages":"Article 100228"},"PeriodicalIF":0.0,"publicationDate":"2022-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2468111322000160","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
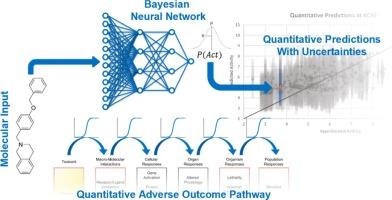
Next-generation risk assessment (NGRA) involves the combination of in vitro and in silico models for more human-relevant, ethical, and sustainable human chemical safety assessment. NGRA requires a quantitative mechanistic understanding of the effects of chemicals across human biology (be they molecular, cellular, organ-level or higher) coupled with a quantitative understanding of the uncertainty in any experimentally measured or predicted values. These values with their uncertainties can then be considered as a probability distribution, which can then be compared to exposure estimates to establish the presence or absence of a margin of safety. We have constructed Bayesian learning neural networks to provide such quantitative predictions and uncertainties for 20 pharmacologically important human molecular initiating events. These models produce high quality quantitative estimates (p(IC50), p(EC50), p(Ki), p(Kd)) of biochemical activity at a molecular initiating event (MIE) with average mean absolute errors (in Log units) of 0.625 ± 0.048 in test data and 0.941 ± 0.215 in external validation data. The key advantage of these models is their ability to also produce standard deviations and credible intervals (CIs) to quantify the uncertainty in these predictions, which we show to be able to distinguish between molecules close to the training data in chemical structure, those less similar to the training data, and decoy compounds drawn from the wider ChEMBL database. These uncertainty values mean that when a prediction is made a user can understand the certainty of the prediction, similar to a quantitative applicability domain, aiding prediction usefulness in NGRA. The ability for in silico methods to produce quantitative predictions with these kinds of probability distributions will be vital to their further use in NGRA, and here clear first steps have been taken.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


