Multimodal attention for lip synthesis using conditional generative adversarial networks
Abstract
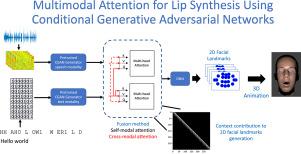
The synthesis of lip movements is an important problem for a socially interactive agent (SIA). It is important to generate lip movements that are synchronized with speech and have realistic co-articulation. We hypothesize that combining lexical information (i.e., sequence of phonemes) and acoustic features can lead not only to models that generate the correct lip movements matching the articulatory movements, but also to trajectories that are well synchronized with the speech emphasis and emotional content. This work presents attention-based frameworks that use acoustic and lexical information to enhance the synthesis of lip movements. The lexical information is obtained from automatic speech recognition (ASR) transcriptions, broadening the range of applications of the proposed solution. We propose models based on conditional generative adversarial networks (CGAN) with self-modality attention and cross-modalities attention mechanisms. These models allow us to understand which frames are considered more in the generation of lip movements. We animate the synthesized lip movements using blendshapes. These animations are used to compare our proposed multimodal models with alternative methods, including unimodal models implemented with either text or acoustic features. We rely on subjective metrics using perceptual evaluations and an objective metric based on the LipSync model. The results show that our proposed models with attention mechanisms are preferred over the baselines on the perception of naturalness. The addition of cross-modality attentions and self-modality attentions has a significant positive impact on the performance of the generated sequences. We observe that lexical information provides valuable information even when the transcriptions are not perfect. The improved performance observed by the multimodal system confirms the complementary information provided by the speech and text modalities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


