{"title":"Classification of cardiac differentiation outcome, percentage of cardiomyocytes on day 10 of differentiation, for hydrogel-encapsulated hiPSCs","authors":"Samira Mohammadi, Mohammadjafar Hashemi, Ferdous Finklea, Bianca Williams, Elizabeth Lipke, Selen Cremaschi","doi":"10.1002/amp2.10148","DOIUrl":null,"url":null,"abstract":"<p>This study employed machine learning (ML) models to predict the cardiomyocyte (CM) content following differentiation of human induced pluripotent stem cells (hiPSCs) encapsulated in hydrogel microspheroids and to identify the main experimental variables affecting the CM yield. Understanding how to enhance CM generation using hiPSCs is critical in moving toward large-scale production and implementing their use in developing therapeutic drugs and regenerative treatments. Cardiomyocyte production has entered a new era with improvements in the differentiation process. However, existing processes are not sufficiently robust for reliable CM manufacturing. Using ML techniques to correlate the initial, experimentally specified stem cell microenvironment's impact on cardiac differentiation could identify important process features. The initial tunable (controlled) input features for training ML models were extracted from 85 individual experiments. Subsets of the controlled input features were selected using feature selection and used for model construction. Random forests, Gaussian process, and support vector machines were employed as the ML models. The models were built to predict two classes of sufficient and insufficient for CM content on differentiation day 10. The best model predicted the sufficient class with an accuracy of 75% and a precision of 71%. The identified key features including post-freeze passage number, media type, PF fibrinogen concentration, CHIR/S/V, axial ratio, and cell concentration provided insight into the significant experimental conditions. This study showed that we can extract information from the experiments and build predictive models that could enhance the cell production process by using ML techniques.</p>","PeriodicalId":87290,"journal":{"name":"Journal of advanced manufacturing and processing","volume":"5 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2022-10-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of advanced manufacturing and processing","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/amp2.10148","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
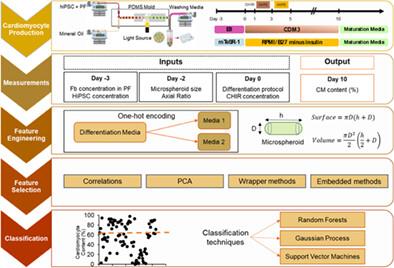
This study employed machine learning (ML) models to predict the cardiomyocyte (CM) content following differentiation of human induced pluripotent stem cells (hiPSCs) encapsulated in hydrogel microspheroids and to identify the main experimental variables affecting the CM yield. Understanding how to enhance CM generation using hiPSCs is critical in moving toward large-scale production and implementing their use in developing therapeutic drugs and regenerative treatments. Cardiomyocyte production has entered a new era with improvements in the differentiation process. However, existing processes are not sufficiently robust for reliable CM manufacturing. Using ML techniques to correlate the initial, experimentally specified stem cell microenvironment's impact on cardiac differentiation could identify important process features. The initial tunable (controlled) input features for training ML models were extracted from 85 individual experiments. Subsets of the controlled input features were selected using feature selection and used for model construction. Random forests, Gaussian process, and support vector machines were employed as the ML models. The models were built to predict two classes of sufficient and insufficient for CM content on differentiation day 10. The best model predicted the sufficient class with an accuracy of 75% and a precision of 71%. The identified key features including post-freeze passage number, media type, PF fibrinogen concentration, CHIR/S/V, axial ratio, and cell concentration provided insight into the significant experimental conditions. This study showed that we can extract information from the experiments and build predictive models that could enhance the cell production process by using ML techniques.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


