Shi Yuan Tang, Athirai A. Irissappane, Frans A. Oliehoek, Jie Zhang
{"title":"Teacher-apprentices RL (TARL): leveraging complex policy distribution through generative adversarial hypernetwork in reinforcement learning","authors":"Shi Yuan Tang, Athirai A. Irissappane, Frans A. Oliehoek, Jie Zhang","doi":"10.1007/s10458-023-09606-9","DOIUrl":null,"url":null,"abstract":"<div><p>Typically, a Reinforcement Learning (RL) algorithm focuses in learning a single deployable policy as the end product. Depending on the initialization methods and seed randomization, learning a single policy could possibly leads to convergence to different local optima across different runs, especially when the algorithm is sensitive to hyper-parameter tuning. Motivated by the capability of Generative Adversarial Networks (GANs) in learning complex data manifold, the adversarial training procedure could be utilized to learn a population of good-performing policies instead. We extend the teacher-student methodology observed in the Knowledge Distillation field in typical deep neural network prediction tasks to RL paradigm. Instead of learning a single compressed student network, an adversarially-trained generative model (hypernetwork) is learned to output network weights of a population of good-performing policy networks, representing a school of apprentices. Our proposed framework, named Teacher-Apprentices RL (TARL), is modular and could be used in conjunction with many existing RL algorithms. We illustrate the performance gain and improved robustness by combining TARL with various types of RL algorithms, including direct policy search Cross-Entropy Method, Q-learning, Actor-Critic, and policy gradient-based methods.</p></div>","PeriodicalId":55586,"journal":{"name":"Autonomous Agents and Multi-Agent Systems","volume":"37 2","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2023-04-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Agents and Multi-Agent Systems","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10458-023-09606-9","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
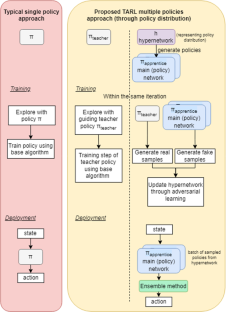
Typically, a Reinforcement Learning (RL) algorithm focuses in learning a single deployable policy as the end product. Depending on the initialization methods and seed randomization, learning a single policy could possibly leads to convergence to different local optima across different runs, especially when the algorithm is sensitive to hyper-parameter tuning. Motivated by the capability of Generative Adversarial Networks (GANs) in learning complex data manifold, the adversarial training procedure could be utilized to learn a population of good-performing policies instead. We extend the teacher-student methodology observed in the Knowledge Distillation field in typical deep neural network prediction tasks to RL paradigm. Instead of learning a single compressed student network, an adversarially-trained generative model (hypernetwork) is learned to output network weights of a population of good-performing policy networks, representing a school of apprentices. Our proposed framework, named Teacher-Apprentices RL (TARL), is modular and could be used in conjunction with many existing RL algorithms. We illustrate the performance gain and improved robustness by combining TARL with various types of RL algorithms, including direct policy search Cross-Entropy Method, Q-learning, Actor-Critic, and policy gradient-based methods.
期刊介绍:
This is the official journal of the International Foundation for Autonomous Agents and Multi-Agent Systems. It provides a leading forum for disseminating significant original research results in the foundations, theory, development, analysis, and applications of autonomous agents and multi-agent systems. Coverage in Autonomous Agents and Multi-Agent Systems includes, but is not limited to:
Agent decision-making architectures and their evaluation, including: cognitive models; knowledge representation; logics for agency; ontological reasoning; planning (single and multi-agent); reasoning (single and multi-agent)
Cooperation and teamwork, including: distributed problem solving; human-robot/agent interaction; multi-user/multi-virtual-agent interaction; coalition formation; coordination
Agent communication languages, including: their semantics, pragmatics, and implementation; agent communication protocols and conversations; agent commitments; speech act theory
Ontologies for agent systems, agents and the semantic web, agents and semantic web services, Grid-based systems, and service-oriented computing
Agent societies and societal issues, including: artificial social systems; environments, organizations and institutions; ethical and legal issues; privacy, safety and security; trust, reliability and reputation
Agent-based system development, including: agent development techniques, tools and environments; agent programming languages; agent specification or validation languages
Agent-based simulation, including: emergent behavior; participatory simulation; simulation techniques, tools and environments; social simulation
Agreement technologies, including: argumentation; collective decision making; judgment aggregation and belief merging; negotiation; norms
Economic paradigms, including: auction and mechanism design; bargaining and negotiation; economically-motivated agents; game theory (cooperative and non-cooperative); social choice and voting
Learning agents, including: computational architectures for learning agents; evolution, adaptation; multi-agent learning.
Robotic agents, including: integrated perception, cognition, and action; cognitive robotics; robot planning (including action and motion planning); multi-robot systems.
Virtual agents, including: agents in games and virtual environments; companion and coaching agents; modeling personality, emotions; multimodal interaction; verbal and non-verbal expressiveness
Significant, novel applications of agent technology
Comprehensive reviews and authoritative tutorials of research and practice in agent systems
Comprehensive and authoritative reviews of books dealing with agents and multi-agent systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


