{"title":"Mapping Chinese Medical Entities to the Unified Medical Language System.","authors":"Luming Chen, Yifan Qi, Aiping Wu, Lizong Deng, Taijiao Jiang","doi":"10.34133/hds.0011","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Chinese medical entities have not been organized comprehensively due to the lack of well-developed terminology systems, which poses a challenge to processing Chinese medical texts for fine-grained medical knowledge representation. To unify Chinese medical terminologies, mapping Chinese medical entities to their English counterparts in the Unified Medical Language System (UMLS) is an efficient solution. However, their mappings have not been investigated sufficiently in former research. In this study, we explore strategies for mapping Chinese medical entities to the UMLS and systematically evaluate the mapping performance.</p><p><strong>Methods: </strong>First, Chinese medical entities are translated to English using multiple web-based translation engines. Then, 3 mapping strategies are investigated: (a) string-based, (b) semantic-based, and (c) string and semantic similarity combined. In addition, cross-lingual pretrained language models are applied to map Chinese medical entities to UMLS concepts without translation. All of these strategies are evaluated on the ICD10-CN, Chinese Human Phenotype Ontology (CHPO), and RealWorld datasets.</p><p><strong>Results: </strong>The linear combination method based on the SapBERT and term frequency-inverse document frequency bag-of-words models perform the best on all evaluation datasets, with 91.85%, 82.44%, and 78.43% of the top 5 accuracies on the ICD10-CN, CHPO, and RealWorld datasets, respectively.</p><p><strong>Conclusions: </strong>In our study, we explore strategies for mapping Chinese medical entities to the UMLS and identify a satisfactory linear combination method. Our investigation will facilitate Chinese medical entity normalization and inspire research that focuses on Chinese medical ontology development.</p>","PeriodicalId":73207,"journal":{"name":"Health data science","volume":"1 1","pages":"0011"},"PeriodicalIF":0.0000,"publicationDate":"2023-03-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10880171/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health data science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.34133/hds.0011","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Chinese medical entities have not been organized comprehensively due to the lack of well-developed terminology systems, which poses a challenge to processing Chinese medical texts for fine-grained medical knowledge representation. To unify Chinese medical terminologies, mapping Chinese medical entities to their English counterparts in the Unified Medical Language System (UMLS) is an efficient solution. However, their mappings have not been investigated sufficiently in former research. In this study, we explore strategies for mapping Chinese medical entities to the UMLS and systematically evaluate the mapping performance.
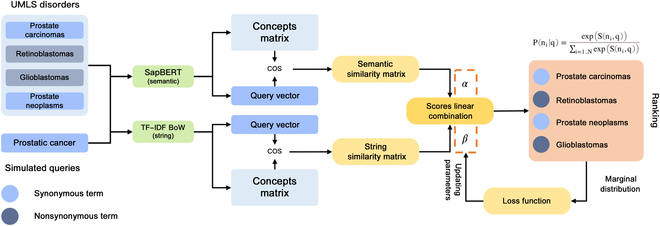
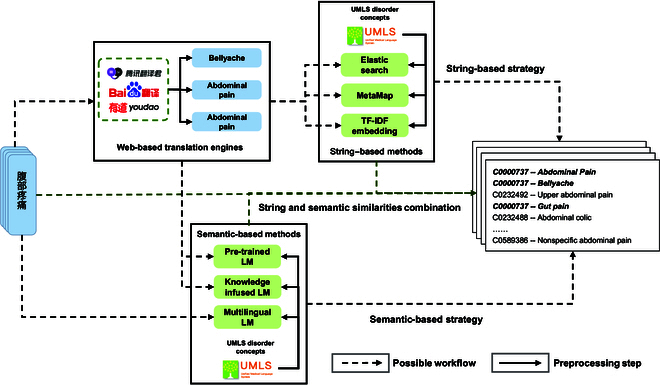
Methods: First, Chinese medical entities are translated to English using multiple web-based translation engines. Then, 3 mapping strategies are investigated: (a) string-based, (b) semantic-based, and (c) string and semantic similarity combined. In addition, cross-lingual pretrained language models are applied to map Chinese medical entities to UMLS concepts without translation. All of these strategies are evaluated on the ICD10-CN, Chinese Human Phenotype Ontology (CHPO), and RealWorld datasets.
Results: The linear combination method based on the SapBERT and term frequency-inverse document frequency bag-of-words models perform the best on all evaluation datasets, with 91.85%, 82.44%, and 78.43% of the top 5 accuracies on the ICD10-CN, CHPO, and RealWorld datasets, respectively.
Conclusions: In our study, we explore strategies for mapping Chinese medical entities to the UMLS and identify a satisfactory linear combination method. Our investigation will facilitate Chinese medical entity normalization and inspire research that focuses on Chinese medical ontology development.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


