Parisa Abedi Khoozani, Vishal Bharmauria, Adrian Schütz, Richard P Wildes, J Douglas Crawford
{"title":"Integration of allocentric and egocentric visual information in a convolutional/multilayer perceptron network model of goal-directed gaze shifts.","authors":"Parisa Abedi Khoozani, Vishal Bharmauria, Adrian Schütz, Richard P Wildes, J Douglas Crawford","doi":"10.1093/texcom/tgac026","DOIUrl":null,"url":null,"abstract":"<p><p>Allocentric (landmark-centered) and egocentric (eye-centered) visual codes are fundamental for spatial cognition, navigation, and goal-directed movement. Neuroimaging and neurophysiology suggest these codes are initially segregated, but then reintegrated in frontal cortex for movement control. We created and validated a theoretical framework for this process using physiologically constrained inputs and outputs. To implement a general framework, we integrated a convolutional neural network (CNN) of the visual system with a multilayer perceptron (MLP) model of the sensorimotor transformation. The network was trained on a task where a landmark shifted relative to the saccade target. These visual parameters were input to the CNN, the CNN output and initial gaze position to the MLP, and a decoder transformed MLP output into saccade vectors. Decoded saccade output replicated idealized training sets with various allocentric weightings and actual monkey data where the landmark shift had a partial influence (<i>R</i> <sup>2</sup> = 0.8). Furthermore, MLP output units accurately simulated prefrontal response field shifts recorded from monkeys during the same paradigm. In summary, our model replicated both the general properties of the visuomotor transformations for gaze and specific experimental results obtained during allocentric-egocentric integration, suggesting it can provide a general framework for understanding these and other complex visuomotor behaviors.</p>","PeriodicalId":72551,"journal":{"name":"Cerebral cortex communications","volume":" ","pages":"tgac026"},"PeriodicalIF":0.0000,"publicationDate":"2022-07-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9334293/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cerebral cortex communications","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/texcom/tgac026","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
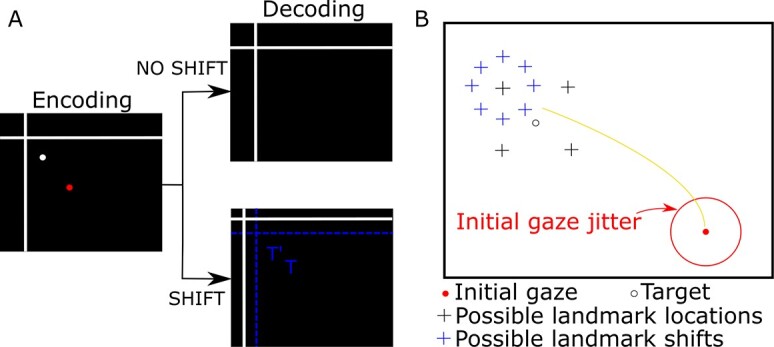
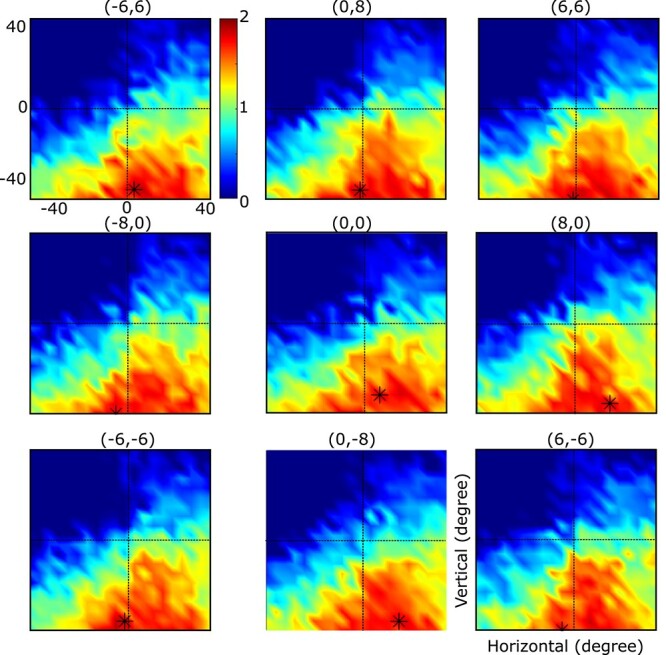
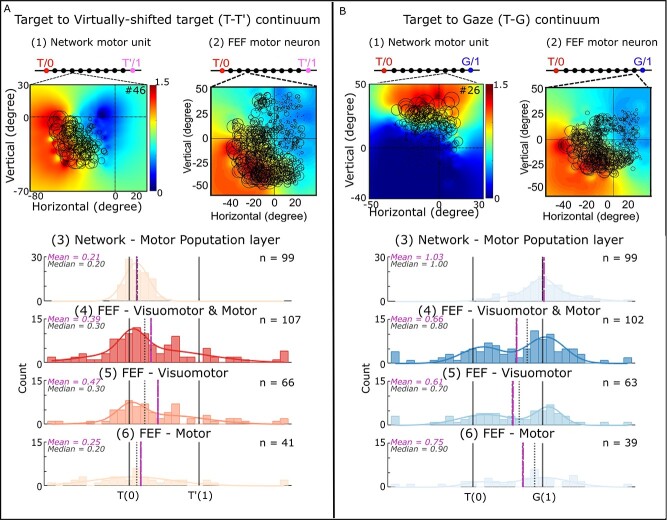
Allocentric (landmark-centered) and egocentric (eye-centered) visual codes are fundamental for spatial cognition, navigation, and goal-directed movement. Neuroimaging and neurophysiology suggest these codes are initially segregated, but then reintegrated in frontal cortex for movement control. We created and validated a theoretical framework for this process using physiologically constrained inputs and outputs. To implement a general framework, we integrated a convolutional neural network (CNN) of the visual system with a multilayer perceptron (MLP) model of the sensorimotor transformation. The network was trained on a task where a landmark shifted relative to the saccade target. These visual parameters were input to the CNN, the CNN output and initial gaze position to the MLP, and a decoder transformed MLP output into saccade vectors. Decoded saccade output replicated idealized training sets with various allocentric weightings and actual monkey data where the landmark shift had a partial influence (R2 = 0.8). Furthermore, MLP output units accurately simulated prefrontal response field shifts recorded from monkeys during the same paradigm. In summary, our model replicated both the general properties of the visuomotor transformations for gaze and specific experimental results obtained during allocentric-egocentric integration, suggesting it can provide a general framework for understanding these and other complex visuomotor behaviors.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


