{"title":"Relation Extraction in Biomedical Texts Based on Multi-Head Attention Model With Syntactic Dependency Feature: Modeling Study.","authors":"Yongbin Li, Linhu Hui, Liping Zou, Huyang Li, Luo Xu, Xiaohua Wang, Stephanie Chua","doi":"10.2196/41136","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>With the rapid expansion of biomedical literature, biomedical information extraction has attracted increasing attention from researchers. In particular, relation extraction between 2 entities is a long-term research topic.</p><p><strong>Objective: </strong>This study aimed to perform 2 multiclass relation extraction tasks of Biomedical Natural Language Processing Workshop 2019 Open Shared Tasks: relation extraction of Bacteria-Biotope (BB-rel) task and binary relation extraction of plant seed development (SeeDev-binary) task. In essence, these 2 tasks are aimed at extracting the relation between annotated entity pairs from biomedical texts, which is a challenging problem.</p><p><strong>Methods: </strong>Traditional research methods adopted feature- or kernel-based methods and achieved good performance. For these tasks, we propose a deep learning model based on a combination of several distributed features, such as domain-specific word embedding, part-of-speech embedding, entity-type embedding, distance embedding, and position embedding. The multi-head attention mechanism is used to extract the global semantic features of an entire sentence. Meanwhile, we introduced a dependency-type feature and the shortest dependency path connecting 2 candidate entities in the syntactic dependency graph to enrich the feature representation.</p><p><strong>Results: </strong>Experiments show that our proposed model has excellent performance in biomedical relation extraction, achieving F<sub>1</sub> scores of 65.56% and 38.04% on the test sets of the BB-rel and SeeDev-binary tasks. Especially in the SeeDev-binary task, the F<sub>1</sub> score of our model is superior to that of other existing models and achieves state-of-the-art performance.</p><p><strong>Conclusions: </strong>We demonstrated that the multi-head attention mechanism can learn relevant syntactic and semantic features in different representation subspaces and different positions to extract comprehensive feature representation. Moreover, syntactic dependency features can improve the performance of the model by learning dependency relation between the entities in biomedical texts.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":" ","pages":"e41136"},"PeriodicalIF":3.8000,"publicationDate":"2022-10-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9634522/pdf/","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/41136","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 3
Abstract
Background: With the rapid expansion of biomedical literature, biomedical information extraction has attracted increasing attention from researchers. In particular, relation extraction between 2 entities is a long-term research topic.
Objective: This study aimed to perform 2 multiclass relation extraction tasks of Biomedical Natural Language Processing Workshop 2019 Open Shared Tasks: relation extraction of Bacteria-Biotope (BB-rel) task and binary relation extraction of plant seed development (SeeDev-binary) task. In essence, these 2 tasks are aimed at extracting the relation between annotated entity pairs from biomedical texts, which is a challenging problem.
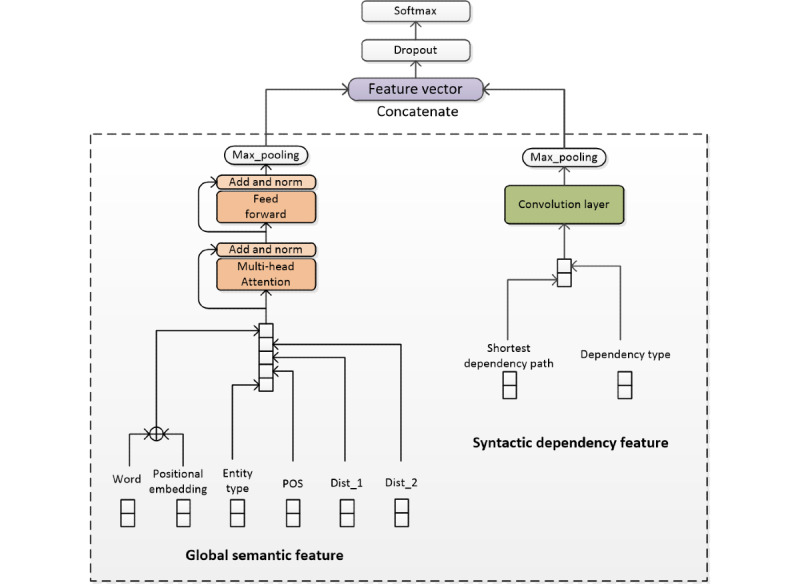
Methods: Traditional research methods adopted feature- or kernel-based methods and achieved good performance. For these tasks, we propose a deep learning model based on a combination of several distributed features, such as domain-specific word embedding, part-of-speech embedding, entity-type embedding, distance embedding, and position embedding. The multi-head attention mechanism is used to extract the global semantic features of an entire sentence. Meanwhile, we introduced a dependency-type feature and the shortest dependency path connecting 2 candidate entities in the syntactic dependency graph to enrich the feature representation.
Results: Experiments show that our proposed model has excellent performance in biomedical relation extraction, achieving F1 scores of 65.56% and 38.04% on the test sets of the BB-rel and SeeDev-binary tasks. Especially in the SeeDev-binary task, the F1 score of our model is superior to that of other existing models and achieves state-of-the-art performance.
Conclusions: We demonstrated that the multi-head attention mechanism can learn relevant syntactic and semantic features in different representation subspaces and different positions to extract comprehensive feature representation. Moreover, syntactic dependency features can improve the performance of the model by learning dependency relation between the entities in biomedical texts.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.
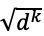
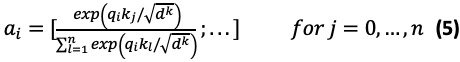

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


