{"title":"Text Mining of Biomedical Articles Using the Konstanz Information Miner (KNIME) Platform: Hemolytic Uremic Syndrome as a Case Study.","authors":"Ricardo A Dorr, Juan J Casal, Roxana Toriano","doi":"10.4258/hir.2022.28.3.276","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Automated systems for information extraction are becoming very useful due to the enormous scale of the existing literature and the increasing number of scientific articles published worldwide in the field of medicine. We aimed to develop an accessible method using the open-source platform KNIME to perform text mining (TM) on indexed publications. Material from scientific publications in the field of life sciences was obtained and integrated by mining information on hemolytic uremic syndrome (HUS) as a case study.</p><p><strong>Methods: </strong>Text retrieved from Europe PubMed Central (PMC) was processed using specific KNIME nodes. The results were presented in the form of tables or graphical representations. Data could also be compared with those from other sources.</p><p><strong>Results: </strong>By applying TM to the scientific literature on HUS as a case study, and by selecting various fields from scientific articles, it was possible to obtain a list of individual authors of publications, build bags of words and study their frequency and temporal use, discriminate topics (HUS vs. atypical HUS) in an unsupervised manner, and cross-reference information with a list of FDA-approved drugs.</p><p><strong>Conclusions: </strong>Following the instructions in the tutorial, researchers without programming skills can successfully perform TM on the indexed scientific literature. This methodology, using KNIME, could become a useful tool for performing statistics, analyzing behaviors, following trends, and making forecast related to medical issues. The advantages of TM using KNIME include enabling the integration of scientific information, helping to carry out reviews, and optimizing the management of resources dedicated to basic and clinical research.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":" ","pages":"276-283"},"PeriodicalIF":2.3000,"publicationDate":"2022-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/99/bc/hir-2022-28-3-276.PMC9388920.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2022.28.3.276","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/7/31 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Automated systems for information extraction are becoming very useful due to the enormous scale of the existing literature and the increasing number of scientific articles published worldwide in the field of medicine. We aimed to develop an accessible method using the open-source platform KNIME to perform text mining (TM) on indexed publications. Material from scientific publications in the field of life sciences was obtained and integrated by mining information on hemolytic uremic syndrome (HUS) as a case study.
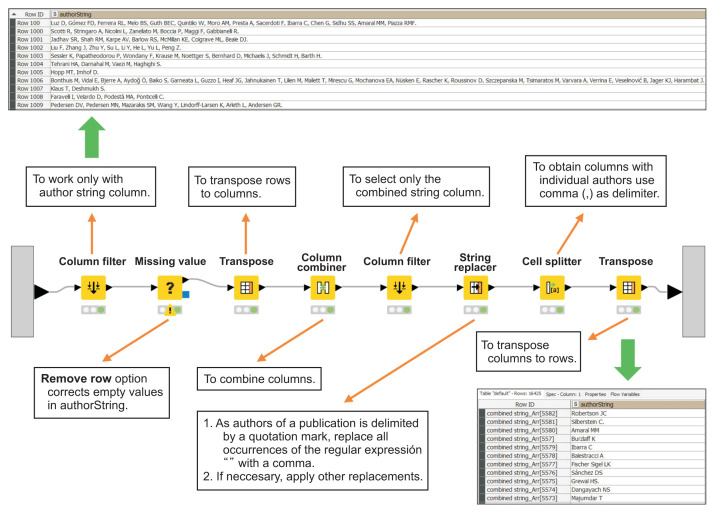
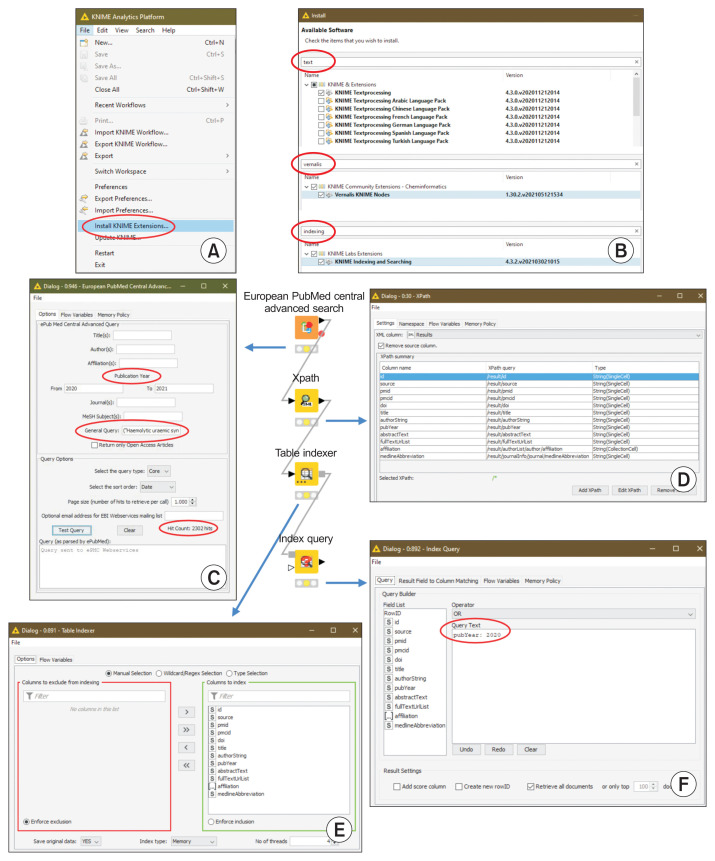
Methods: Text retrieved from Europe PubMed Central (PMC) was processed using specific KNIME nodes. The results were presented in the form of tables or graphical representations. Data could also be compared with those from other sources.
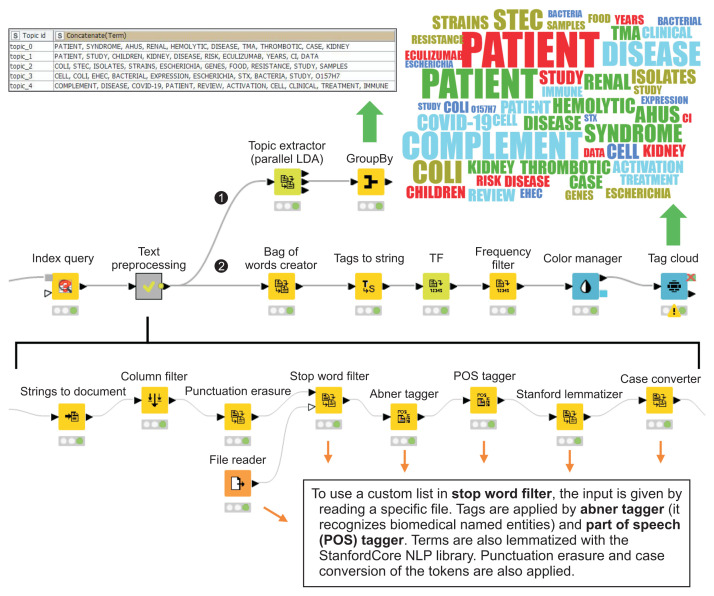
Results: By applying TM to the scientific literature on HUS as a case study, and by selecting various fields from scientific articles, it was possible to obtain a list of individual authors of publications, build bags of words and study their frequency and temporal use, discriminate topics (HUS vs. atypical HUS) in an unsupervised manner, and cross-reference information with a list of FDA-approved drugs.
Conclusions: Following the instructions in the tutorial, researchers without programming skills can successfully perform TM on the indexed scientific literature. This methodology, using KNIME, could become a useful tool for performing statistics, analyzing behaviors, following trends, and making forecast related to medical issues. The advantages of TM using KNIME include enabling the integration of scientific information, helping to carry out reviews, and optimizing the management of resources dedicated to basic and clinical research.
目的:由于现有文献的巨大规模和全球医学领域发表的科学文章数量的增加,信息提取的自动化系统正变得非常有用。我们的目标是开发一种可访问的方法,使用开源平台KNIME对索引出版物执行文本挖掘(TM)。从生命科学领域的科学出版物中获得材料,并通过挖掘溶血性尿毒症综合征(HUS)的信息作为案例研究进行整合。方法:从欧洲PubMed Central (PMC)检索的文本使用特定的KNIME节点进行处理。结果以表格或图形的形式呈现。数据也可以与其他来源的数据进行比较。结果:通过将TM应用于关于溶血性尿毒综合征的科学文献作为案例研究,并从科学文章中选择不同的领域,可以获得出版物的个人作者列表,建立单词袋并研究其使用频率和时间,以无监督的方式区分主题(溶血性尿毒综合征与非典型溶血性尿毒综合征),并与fda批准的药物列表交叉参考信息。结论:没有编程技能的研究人员可以按照教程的指导,成功地对已索引的科学文献进行TM。这种使用KNIME的方法可以成为进行统计、分析行为、跟踪趋势和做出与医疗问题相关的预测的有用工具。使用KNIME的TM的优势包括能够整合科学信息,帮助进行审查,并优化用于基础和临床研究的资源管理。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


