{"title":"Modeling Individual Patient Count/Rate Data over Time with Applications to Cancer Pain Flares and Cancer Pain Medication Usage.","authors":"George J Knafl, Salimah H Meghani","doi":"10.4236/ojs.2021.115038","DOIUrl":null,"url":null,"abstract":"<p><p>The purpose of this article is to investigate approaches for modeling individual patient count/rate data over time accounting for temporal correlation and non-constant dispersions while requiring reasonable amounts of time to search over alternative models for those data. This research addresses formulations for two approaches for extending generalized estimating equations (GEE) modeling. These approaches use a likelihood-like function based on the multivariate normal density. The first approach augments standard GEE equations to include equations for estimation of dispersion parameters. The second approach is based on estimating equations determined by partial derivatives of the likelihood-like function with respect to all model parameters and so extends linear mixed modeling. Three correlation structures are considered including independent, exchangeable, and spatial autoregressive of order 1 correlations. The likelihood-like function is used to formulate a likelihood-like cross-validation (LCV) score for use in evaluating models. Example analyses are presented using these two modeling approaches applied to three data sets of counts/rates over time for individual cancer patients including pain flares per day, as needed pain medications taken per day, and around the clock pain medications taken per day per dose. Means and dispersions are modeled as possibly nonlinear functions of time using adaptive regression modeling methods to search through alternative models compared using LCV scores. The results of these analyses demonstrate that extended linear mixed modeling is preferable for modeling individual patient count/rate data over time, because in example analyses, it either generates better LCV scores or more parsimonious models and requires substantially less time.</p>","PeriodicalId":59624,"journal":{"name":"统计学期刊(英文)","volume":"11 5","pages":"633-654"},"PeriodicalIF":0.0000,"publicationDate":"2021-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9351387/pdf/","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"统计学期刊(英文)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4236/ojs.2021.115038","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/9/30 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 5
Abstract
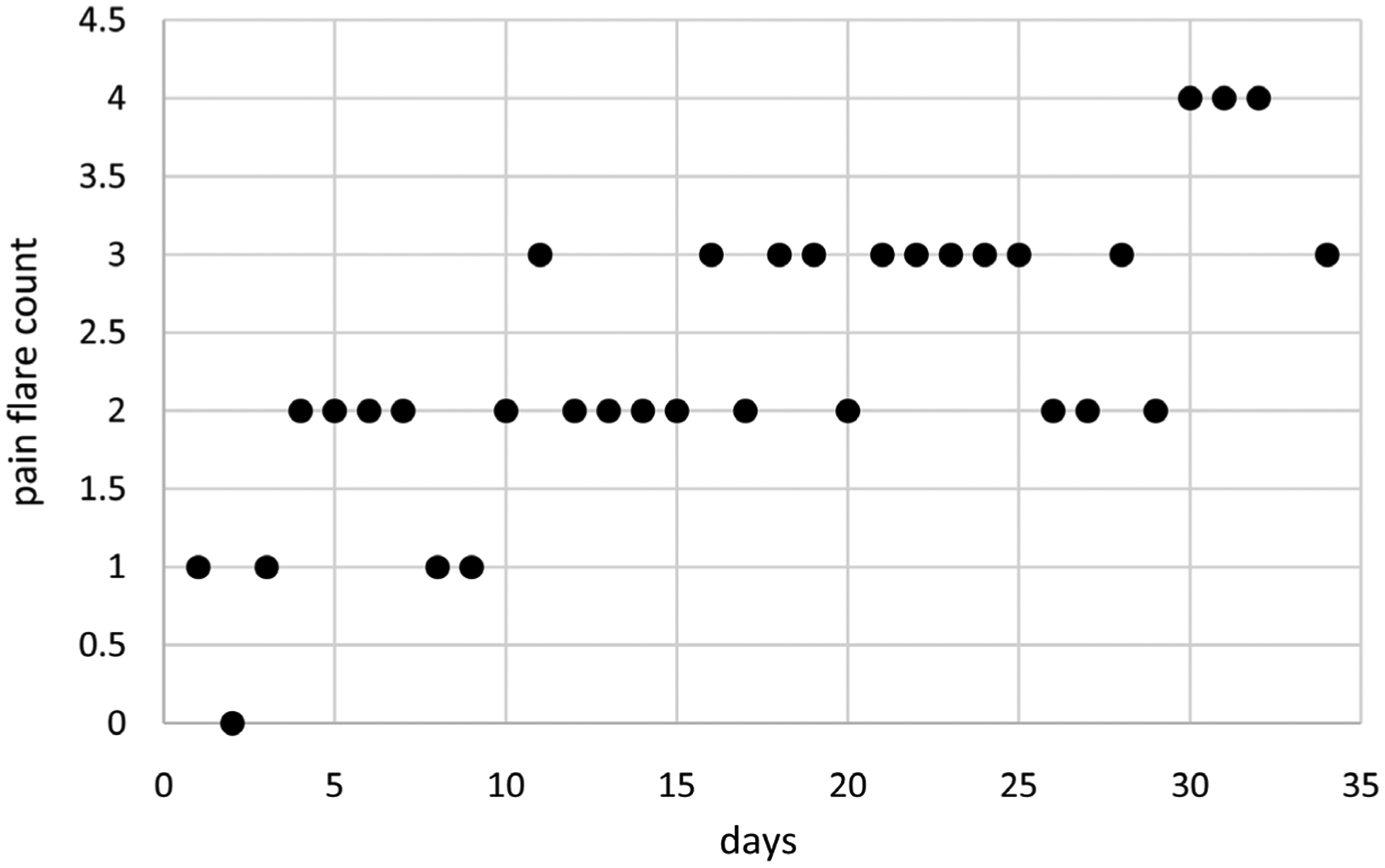
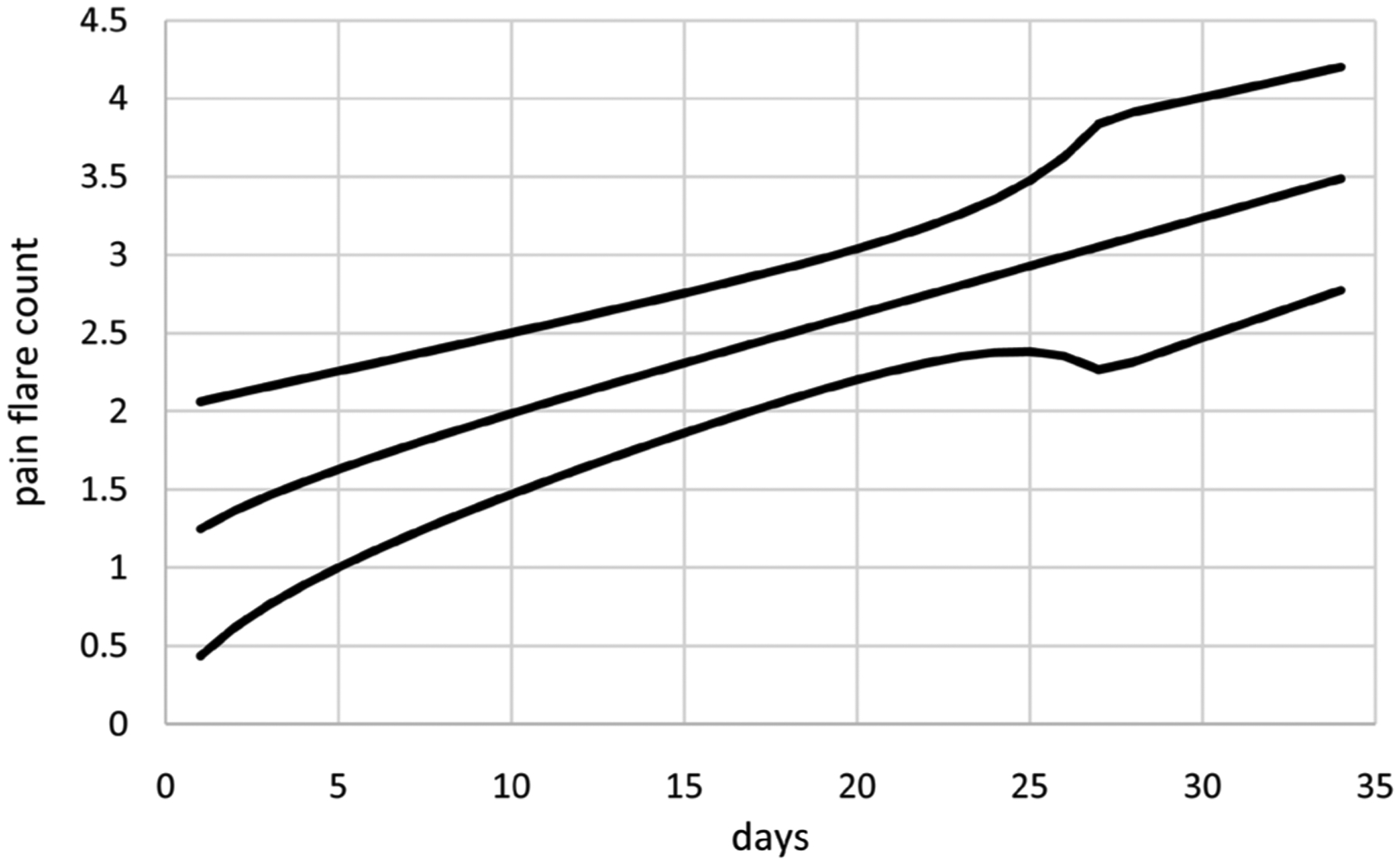
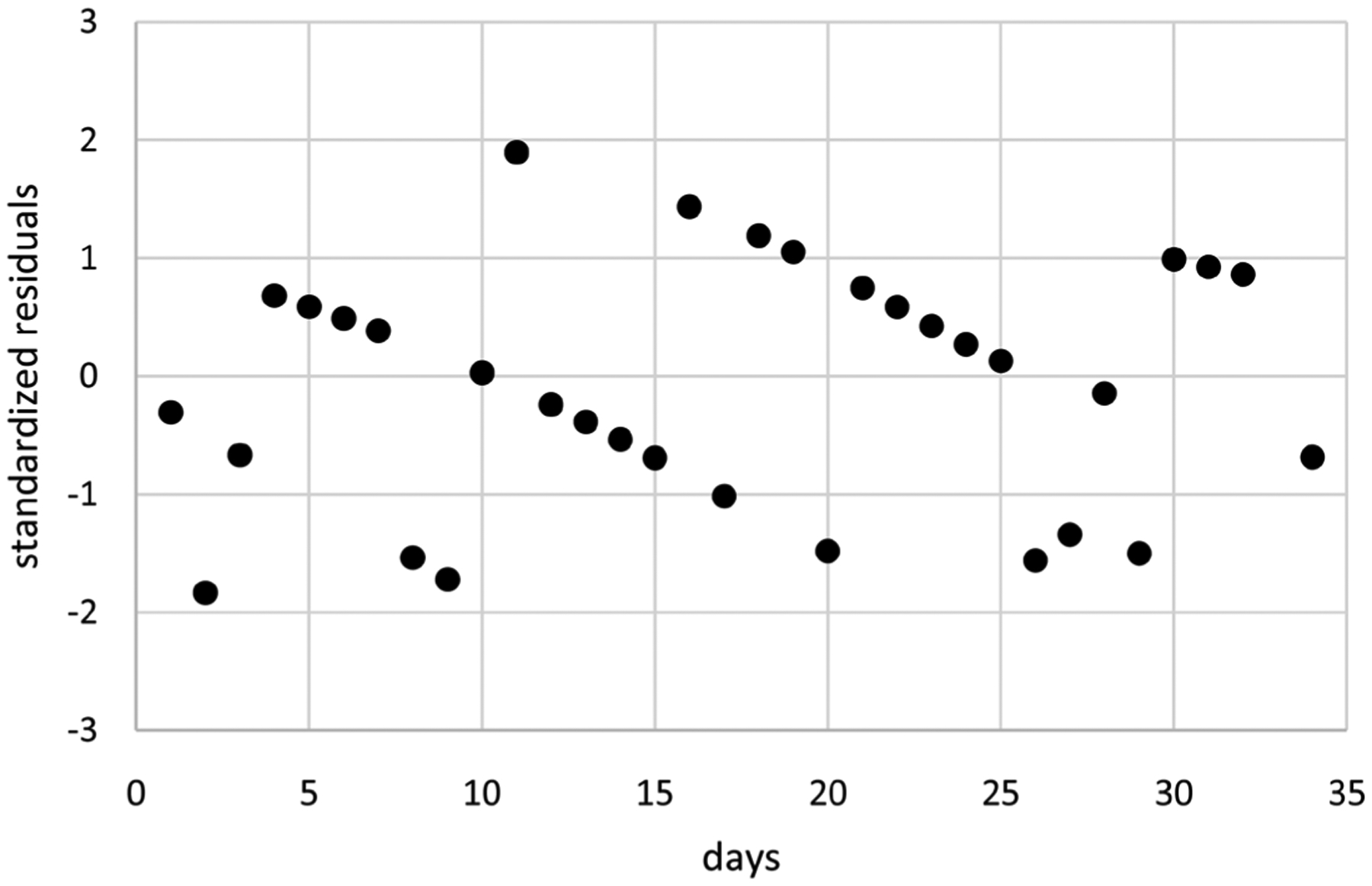
The purpose of this article is to investigate approaches for modeling individual patient count/rate data over time accounting for temporal correlation and non-constant dispersions while requiring reasonable amounts of time to search over alternative models for those data. This research addresses formulations for two approaches for extending generalized estimating equations (GEE) modeling. These approaches use a likelihood-like function based on the multivariate normal density. The first approach augments standard GEE equations to include equations for estimation of dispersion parameters. The second approach is based on estimating equations determined by partial derivatives of the likelihood-like function with respect to all model parameters and so extends linear mixed modeling. Three correlation structures are considered including independent, exchangeable, and spatial autoregressive of order 1 correlations. The likelihood-like function is used to formulate a likelihood-like cross-validation (LCV) score for use in evaluating models. Example analyses are presented using these two modeling approaches applied to three data sets of counts/rates over time for individual cancer patients including pain flares per day, as needed pain medications taken per day, and around the clock pain medications taken per day per dose. Means and dispersions are modeled as possibly nonlinear functions of time using adaptive regression modeling methods to search through alternative models compared using LCV scores. The results of these analyses demonstrate that extended linear mixed modeling is preferable for modeling individual patient count/rate data over time, because in example analyses, it either generates better LCV scores or more parsimonious models and requires substantially less time.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


