Steven Simon, Divneet Mandair, Abdel Albakri, Alison Fohner, Noah Simon, Leslie Lange, Mary Biggs, Kenneth Mukamal, Bruce Psaty, Michael Rosenberg
{"title":"The Impact of Time Horizon on Classification Accuracy: Application of Machine Learning to Prediction of Incident Coronary Heart Disease.","authors":"Steven Simon, Divneet Mandair, Abdel Albakri, Alison Fohner, Noah Simon, Leslie Lange, Mary Biggs, Kenneth Mukamal, Bruce Psaty, Michael Rosenberg","doi":"10.2196/38040","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Many machine learning approaches are limited to classification of outcomes rather than longitudinal prediction. One strategy to use machine learning in clinical risk prediction is to classify outcomes over a given time horizon. However, it is not well-known how to identify the optimal time horizon for risk prediction.</p><p><strong>Objective: </strong>In this study, we aim to identify an optimal time horizon for classification of incident myocardial infarction (MI) using machine learning approaches looped over outcomes with increasing time horizons. Additionally, we sought to compare the performance of these models with the traditional Framingham Heart Study (FHS) coronary heart disease gender-specific Cox proportional hazards regression model.</p><p><strong>Methods: </strong>We analyzed data from a single clinic visit of 5201 participants of a cardiovascular health study. We examined 61 variables collected from this baseline exam, including demographic and biologic data, medical history, medications, serum biomarkers, electrocardiographic, and echocardiographic data. We compared several machine learning methods (eg, random forest, L1 regression, gradient boosted decision tree, support vector machine, and k-nearest neighbor) trained to predict incident MI that occurred within time horizons ranging from 500-10,000 days of follow-up. Models were compared on a 20% held-out testing set using area under the receiver operating characteristic curve (AUROC). Variable importance was performed for random forest and L1 regression models across time points. We compared results with the FHS coronary heart disease gender-specific Cox proportional hazards regression functions.</p><p><strong>Results: </strong>There were 4190 participants included in the analysis, with 2522 (60.2%) female participants and an average age of 72.6 years. Over 10,000 days of follow-up, there were 813 incident MI events. The machine learning models were most predictive over moderate follow-up time horizons (ie, 1500-2500 days). Overall, the L1 (Lasso) logistic regression demonstrated the strongest classification accuracy across all time horizons. This model was most predictive at 1500 days follow-up, with an AUROC of 0.71. The most influential variables differed by follow-up time and model, with gender being the most important feature for the L1 regression and weight for the random forest model across all time frames. Compared with the Framingham Cox function, the L1 and random forest models performed better across all time frames beyond 1500 days.</p><p><strong>Conclusions: </strong>In a population free of coronary heart disease, machine learning techniques can be used to predict incident MI at varying time horizons with reasonable accuracy, with the strongest prediction accuracy in moderate follow-up periods. Validation across additional populations is needed to confirm the validity of this approach in risk prediction.</p>","PeriodicalId":14706,"journal":{"name":"JMIR Cardio","volume":" ","pages":"e38040"},"PeriodicalIF":0.0000,"publicationDate":"2022-11-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9669890/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cardio","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/38040","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 1
Abstract
Background: Many machine learning approaches are limited to classification of outcomes rather than longitudinal prediction. One strategy to use machine learning in clinical risk prediction is to classify outcomes over a given time horizon. However, it is not well-known how to identify the optimal time horizon for risk prediction.
Objective: In this study, we aim to identify an optimal time horizon for classification of incident myocardial infarction (MI) using machine learning approaches looped over outcomes with increasing time horizons. Additionally, we sought to compare the performance of these models with the traditional Framingham Heart Study (FHS) coronary heart disease gender-specific Cox proportional hazards regression model.
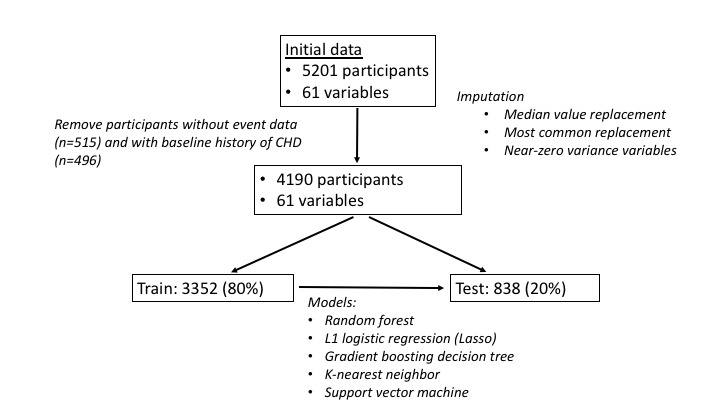
Methods: We analyzed data from a single clinic visit of 5201 participants of a cardiovascular health study. We examined 61 variables collected from this baseline exam, including demographic and biologic data, medical history, medications, serum biomarkers, electrocardiographic, and echocardiographic data. We compared several machine learning methods (eg, random forest, L1 regression, gradient boosted decision tree, support vector machine, and k-nearest neighbor) trained to predict incident MI that occurred within time horizons ranging from 500-10,000 days of follow-up. Models were compared on a 20% held-out testing set using area under the receiver operating characteristic curve (AUROC). Variable importance was performed for random forest and L1 regression models across time points. We compared results with the FHS coronary heart disease gender-specific Cox proportional hazards regression functions.
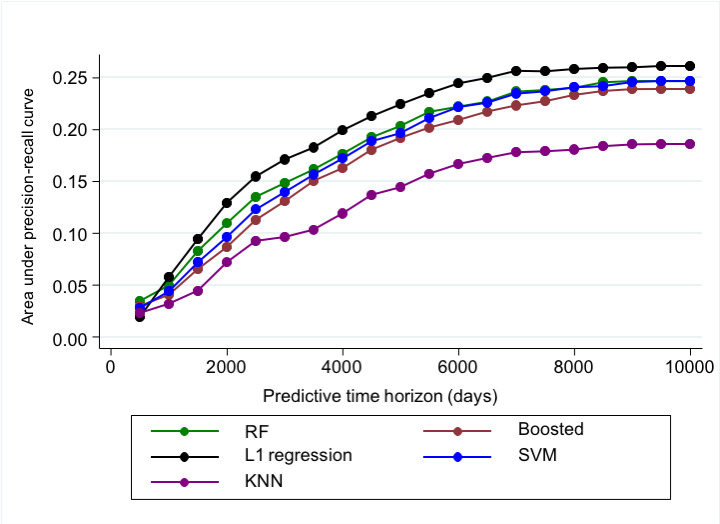
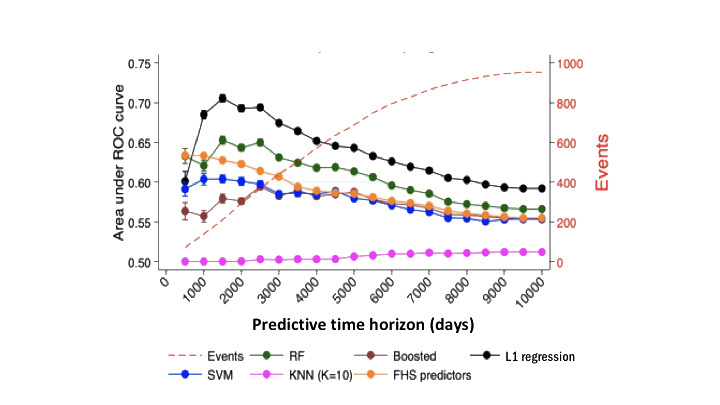
Results: There were 4190 participants included in the analysis, with 2522 (60.2%) female participants and an average age of 72.6 years. Over 10,000 days of follow-up, there were 813 incident MI events. The machine learning models were most predictive over moderate follow-up time horizons (ie, 1500-2500 days). Overall, the L1 (Lasso) logistic regression demonstrated the strongest classification accuracy across all time horizons. This model was most predictive at 1500 days follow-up, with an AUROC of 0.71. The most influential variables differed by follow-up time and model, with gender being the most important feature for the L1 regression and weight for the random forest model across all time frames. Compared with the Framingham Cox function, the L1 and random forest models performed better across all time frames beyond 1500 days.
Conclusions: In a population free of coronary heart disease, machine learning techniques can be used to predict incident MI at varying time horizons with reasonable accuracy, with the strongest prediction accuracy in moderate follow-up periods. Validation across additional populations is needed to confirm the validity of this approach in risk prediction.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


