Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics.
IF 5
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 1
Abstract
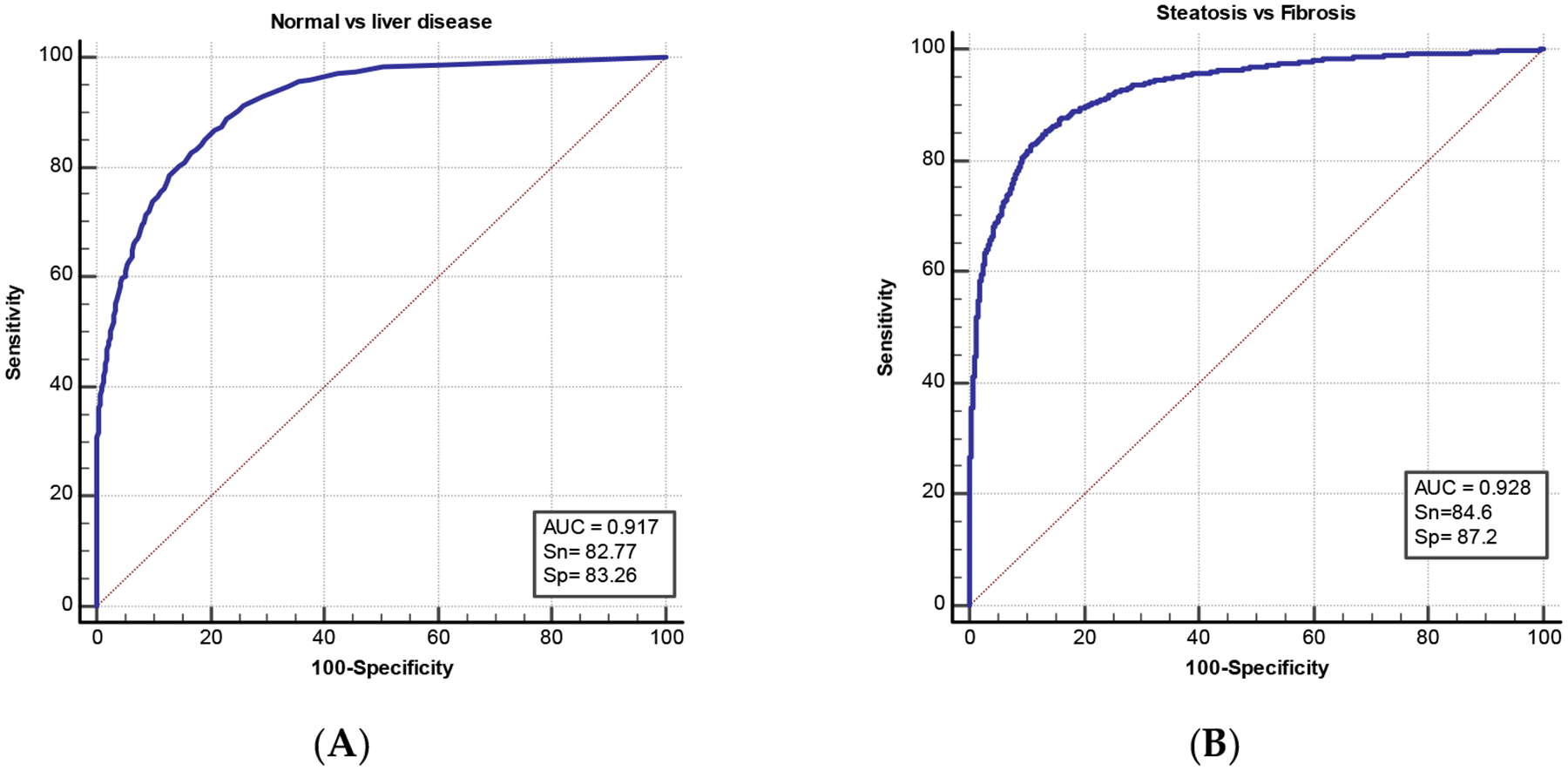
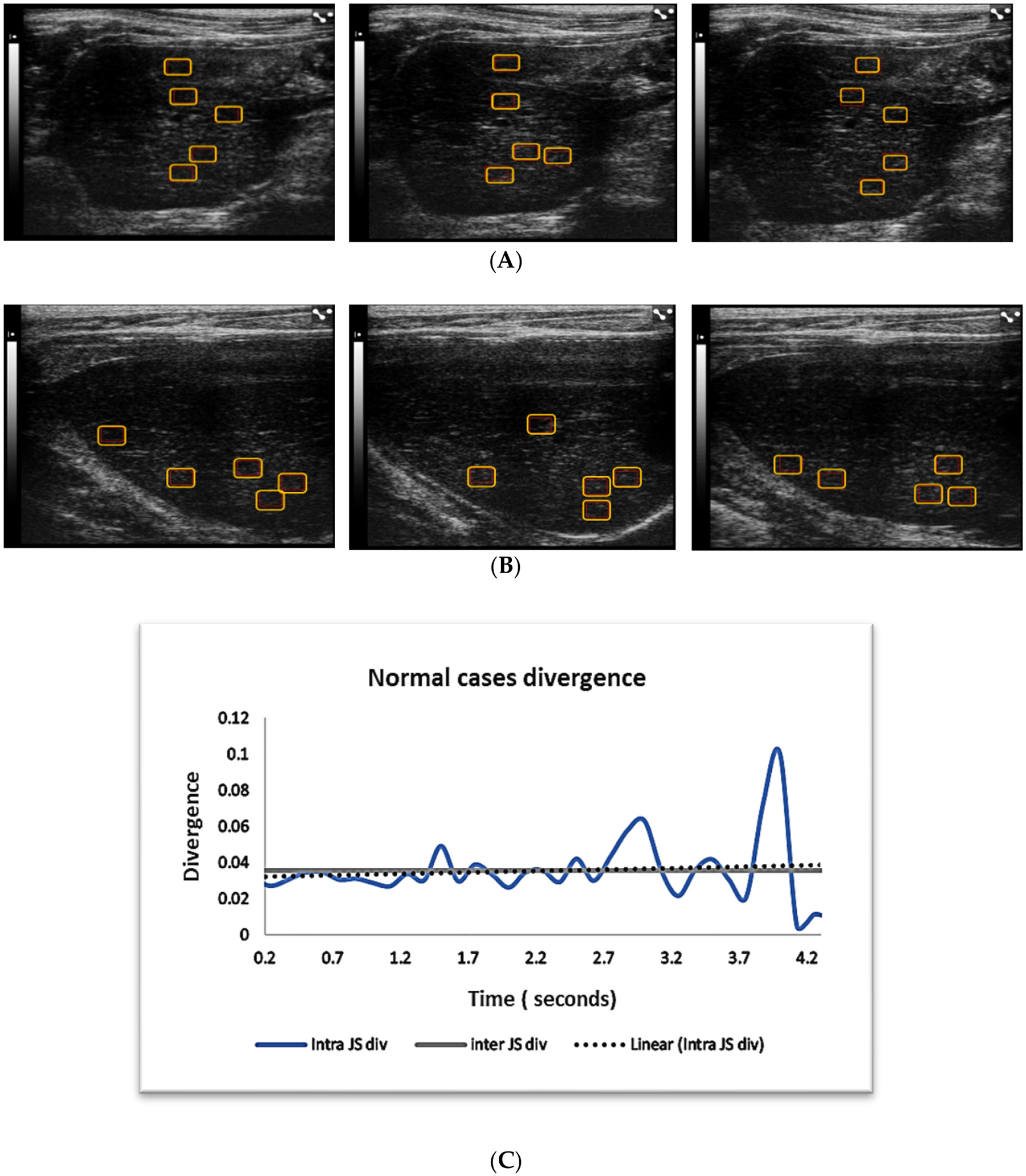
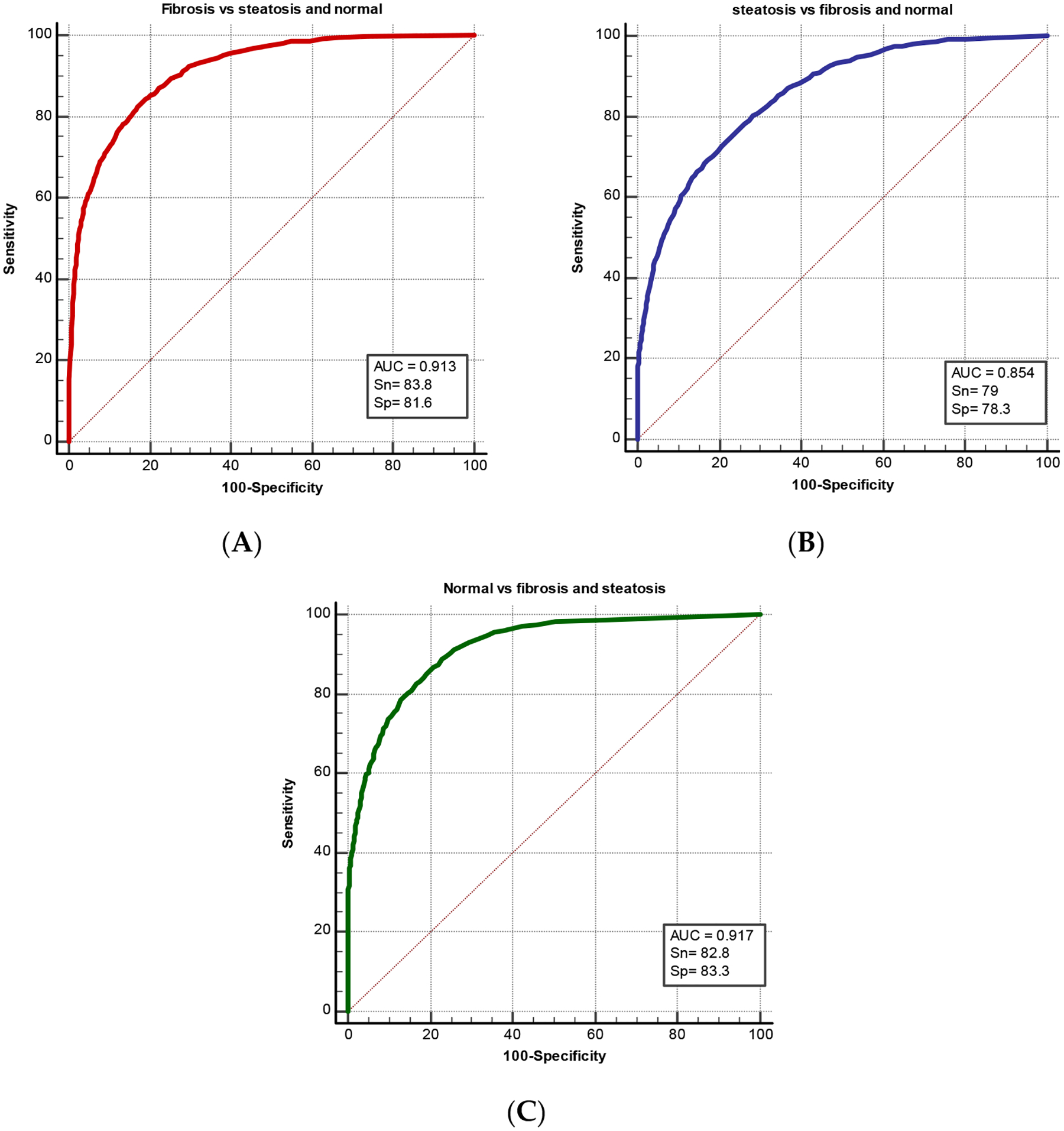
Machine learning for medical imaging not only requires sufficient amounts of data for training and testing but also that the data be independent. It is common to see highly interdependent data whenever there are inherent correlations between observations. This is especially to be expected for sequential imaging data taken from time series. In this study, we evaluate the use of statistical measures to test the independence of sequential ultrasound image data taken from the same case. A total of 1180 B-mode liver ultrasound images with 5903 regions of interests were analyzed. The ultrasound images were taken from two liver disease groups, fibrosis and steatosis, as well as normal cases. Computer-extracted texture features were then used to train a machine learning (ML) model for computer-aided diagnosis. The experiment resulted in high two-category diagnosis using logistic regression, with AUC of 0.928 and high performance of multicategory classification, using random forest ML, with AUC of 0.917. To evaluate the image region independence for machine learning, Jenson–Shannon (JS) divergence was used. JS distributions showed that images of normal liver were independent from each other, while the images from the two disease pathologies were not independent. To guarantee the generalizability of machine learning models, and to prevent data leakage, multiple frames of image data acquired of the same object should be tested for independence before machine learning. Such tests can be applied to real-world medical image problems to determine if images from the same subject can be used for training.
来自同一对象的连续图像可以用于训练机器学习模型吗?超声放射组学检测肝脏疾病的案例研究。
医学成像的机器学习不仅需要足够的数据进行训练和测试,而且需要数据是独立的。每当观测结果之间存在固有相关性时,就会看到高度相互依赖的数据。这尤其适用于从时间序列中获取的连续成像数据。在本研究中,我们评估了使用统计措施来测试从同一病例中获取的连续超声图像数据的独立性。共分析肝脏b超1180张,5903个感兴趣区域。超声图像取自两组肝脏疾病,纤维化和脂肪变性,以及正常病例。然后使用计算机提取的纹理特征来训练用于计算机辅助诊断的机器学习(ML)模型。实验结果表明,采用logistic回归的两类诊断效果良好,AUC为0.928;采用随机森林ML的多类分类效果良好,AUC为0.917。为了评估机器学习的图像区域独立性,使用了jensen - shannon (JS)散度。JS分布显示正常肝脏的图像相互独立,而两种疾病病理的图像不独立。为了保证机器学习模型的泛化性,防止数据泄露,在机器学习之前,需要对同一对象的多帧图像数据进行独立性测试。这些测试可以应用于现实世界的医学图像问题,以确定来自同一主题的图像是否可以用于训练。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


