Raphaël Gazzotti, Catherine Faron, Fabien Gandon, Virginie Lacroix-Hugues, David Darmon
{"title":"Extending electronic medical records vector models with knowledge graphs to improve hospitalization prediction.","authors":"Raphaël Gazzotti, Catherine Faron, Fabien Gandon, Virginie Lacroix-Hugues, David Darmon","doi":"10.1186/s13326-022-00261-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence methods applied to electronic medical records (EMRs) hold the potential to help physicians save time by sharpening their analysis and decisions, thereby improving the health of patients. On the one hand, machine learning algorithms have proven their effectiveness in extracting information and exploiting knowledge extracted from data. On the other hand, knowledge graphs capture human knowledge by relying on conceptual schemas and formalization and supporting reasoning. Leveraging knowledge graphs that are legion in the medical field, it is possible to pre-process and enrich data representation used by machine learning algorithms. Medical data standardization is an opportunity to jointly exploit the richness of knowledge graphs and the capabilities of machine learning algorithms.</p><p><strong>Methods: </strong>We propose to address the problem of hospitalization prediction for patients with an approach that enriches vector representation of EMRs with information extracted from different knowledge graphs before learning and predicting. In addition, we performed an automatic selection of features resulting from knowledge graphs to distinguish noisy ones from those that can benefit the decision making. We report the results of our experiments on the PRIMEGE PACA database that contains more than 600,000 consultations carried out by 17 general practitioners (GPs).</p><p><strong>Results: </strong>A statistical evaluation shows that our proposed approach improves hospitalization prediction. More precisely, injecting features extracted from cross-domain knowledge graphs in the vector representation of EMRs given as input to the prediction algorithm significantly increases the F1 score of the prediction.</p><p><strong>Conclusions: </strong>By injecting knowledge from recognized reference sources into the representation of EMRs, it is possible to significantly improve the prediction of medical events. Future work would be to evaluate the impact of a feature selection step coupled with a combination of features extracted from several knowledge graphs. A possible avenue is to study more hierarchical levels and properties related to concepts, as well as to integrate more semantic annotators to exploit unstructured data.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":" ","pages":"6"},"PeriodicalIF":2.0000,"publicationDate":"2022-02-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8861628/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-022-00261-9","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 1
Abstract
Background: Artificial intelligence methods applied to electronic medical records (EMRs) hold the potential to help physicians save time by sharpening their analysis and decisions, thereby improving the health of patients. On the one hand, machine learning algorithms have proven their effectiveness in extracting information and exploiting knowledge extracted from data. On the other hand, knowledge graphs capture human knowledge by relying on conceptual schemas and formalization and supporting reasoning. Leveraging knowledge graphs that are legion in the medical field, it is possible to pre-process and enrich data representation used by machine learning algorithms. Medical data standardization is an opportunity to jointly exploit the richness of knowledge graphs and the capabilities of machine learning algorithms.
Methods: We propose to address the problem of hospitalization prediction for patients with an approach that enriches vector representation of EMRs with information extracted from different knowledge graphs before learning and predicting. In addition, we performed an automatic selection of features resulting from knowledge graphs to distinguish noisy ones from those that can benefit the decision making. We report the results of our experiments on the PRIMEGE PACA database that contains more than 600,000 consultations carried out by 17 general practitioners (GPs).
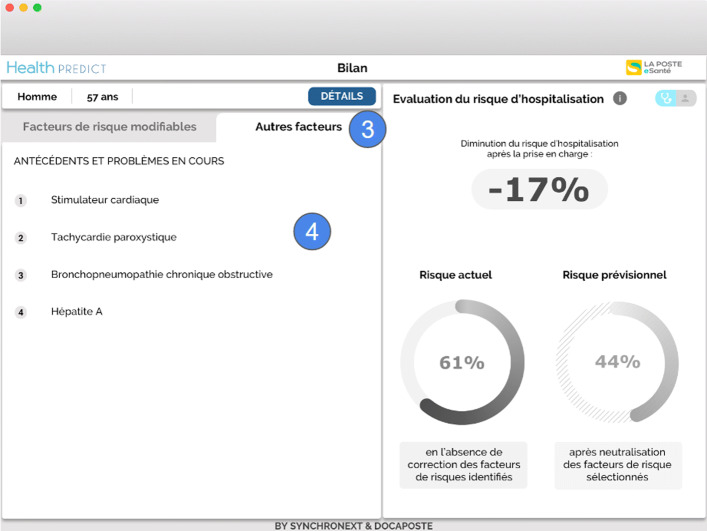
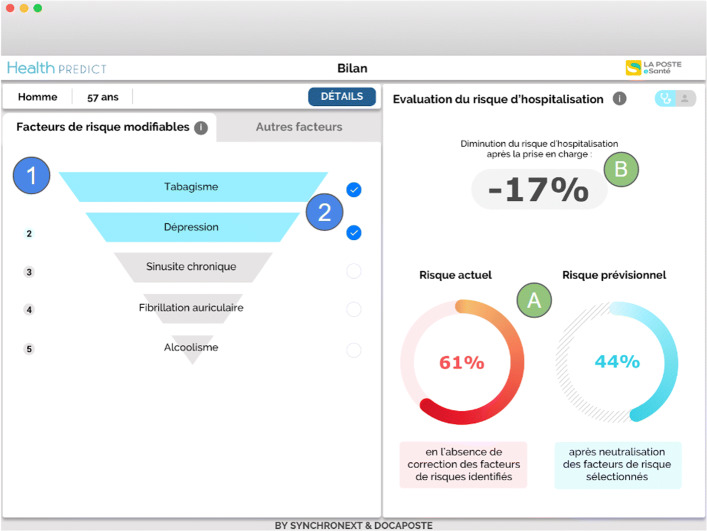
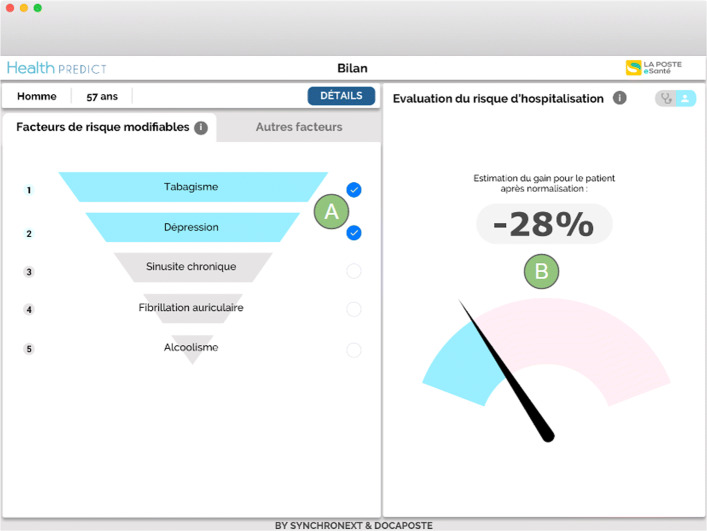
Results: A statistical evaluation shows that our proposed approach improves hospitalization prediction. More precisely, injecting features extracted from cross-domain knowledge graphs in the vector representation of EMRs given as input to the prediction algorithm significantly increases the F1 score of the prediction.
Conclusions: By injecting knowledge from recognized reference sources into the representation of EMRs, it is possible to significantly improve the prediction of medical events. Future work would be to evaluate the impact of a feature selection step coupled with a combination of features extracted from several knowledge graphs. A possible avenue is to study more hierarchical levels and properties related to concepts, as well as to integrate more semantic annotators to exploit unstructured data.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


