{"title":"Disambiguating Clinical Abbreviations Using a One-Fits-All Classifier Based on Deep Learning Techniques.","authors":"Areej Jaber, Paloma Martínez","doi":"10.1055/s-0042-1742388","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Abbreviations are considered an essential part of the clinical narrative; they are used not only to save time and space but also to hide serious or incurable illnesses. Misreckoning interpretation of the clinical abbreviations could affect different aspects concerning patients themselves or other services like clinical support systems. There is no consensus in the scientific community to create new abbreviations, making it difficult to understand them. Disambiguate clinical abbreviations aim to predict the exact meaning of the abbreviation based on context, a crucial step in understanding clinical notes.</p><p><strong>Objectives: </strong>Disambiguating clinical abbreviations is an essential task in information extraction from medical texts. Deep contextualized representations models showed promising results in most word sense disambiguation tasks. In this work, we propose a one-fits-all classifier to disambiguate clinical abbreviations with deep contextualized representation from pretrained language models like Bidirectional Encoder Representation from Transformers (BERT).</p><p><strong>Methods: </strong>A set of experiments with different pretrained clinical BERT models were performed to investigate fine-tuning methods on the disambiguation of clinical abbreviations. One-fits-all classifiers were used to improve disambiguating rare clinical abbreviations.</p><p><strong>Results: </strong>One-fits-all classifiers with deep contextualized representations from Bioclinical, BlueBERT, and MS_BERT pretrained models improved the accuracy using the University of Minnesota data set. The model achieved 98.99, 98.75, and 99.13%, respectively. All the models outperform the state-of-the-art in the previous work of around 98.39%, with the best accuracy using the MS_BERT model.</p><p><strong>Conclusion: </strong>Deep contextualized representations via fine-tuning of pretrained language modeling proved its sufficiency on disambiguating clinical abbreviations; it could be robust for rare and unseen abbreviations and has the advantage of avoiding building a separate classifier for each abbreviation. Transfer learning can improve the development of practical abbreviation disambiguation systems.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":" ","pages":"e28-e34"},"PeriodicalIF":1.8000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/79/7a/10-1055-s-0042-1742388.PMC9246508.pdf","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0042-1742388","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/2/1 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 9
Abstract
Background: Abbreviations are considered an essential part of the clinical narrative; they are used not only to save time and space but also to hide serious or incurable illnesses. Misreckoning interpretation of the clinical abbreviations could affect different aspects concerning patients themselves or other services like clinical support systems. There is no consensus in the scientific community to create new abbreviations, making it difficult to understand them. Disambiguate clinical abbreviations aim to predict the exact meaning of the abbreviation based on context, a crucial step in understanding clinical notes.
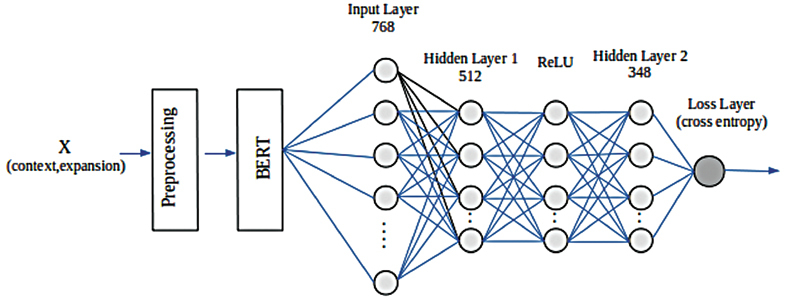
Objectives: Disambiguating clinical abbreviations is an essential task in information extraction from medical texts. Deep contextualized representations models showed promising results in most word sense disambiguation tasks. In this work, we propose a one-fits-all classifier to disambiguate clinical abbreviations with deep contextualized representation from pretrained language models like Bidirectional Encoder Representation from Transformers (BERT).
Methods: A set of experiments with different pretrained clinical BERT models were performed to investigate fine-tuning methods on the disambiguation of clinical abbreviations. One-fits-all classifiers were used to improve disambiguating rare clinical abbreviations.
Results: One-fits-all classifiers with deep contextualized representations from Bioclinical, BlueBERT, and MS_BERT pretrained models improved the accuracy using the University of Minnesota data set. The model achieved 98.99, 98.75, and 99.13%, respectively. All the models outperform the state-of-the-art in the previous work of around 98.39%, with the best accuracy using the MS_BERT model.
Conclusion: Deep contextualized representations via fine-tuning of pretrained language modeling proved its sufficiency on disambiguating clinical abbreviations; it could be robust for rare and unseen abbreviations and has the advantage of avoiding building a separate classifier for each abbreviation. Transfer learning can improve the development of practical abbreviation disambiguation systems.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


