Runzhao Li , Jose Martin Herreros , Athanasios Tsolakis , Wenzhao Yang
{"title":"Machine learning and deep learning enabled fuel sooting tendency prediction from molecular structure","authors":"Runzhao Li , Jose Martin Herreros , Athanasios Tsolakis , Wenzhao Yang","doi":"10.1016/j.jmgm.2021.108083","DOIUrl":null,"url":null,"abstract":"<div><p><span>Soot formation models become increasingly important in advanced renewable fuels formulation for soot reduction benefit. This work evaluates performance of machine learning<span> (ML) and deep learning<span> (DL) to predict yield sooting index (YSI) from chemical structure and proposes a tailor-made convolution neural network (CNN)-SDSeries38 for </span></span></span>regression problem<span><span><span>. In ML, a novel quantitative structure-property relationship (QSPR) is developed for feature extraction and the relationship between molecular structure and YSI is built by ML algorithm. In DL, SDSeries38 contains 9 </span>feature learning modules, 1 regression module for automated feature learning and regression. It adopts standard series </span>network architecture<span><span> and modular structure, each feature learning module is a stack of convolution, batch normalization<span><span>, activation, pooling layers. ML-QSPR model outperforms SDSeries38 in accuracy (RMSE = 7.563 vs 19.58), computational speed and the former applies to fuel mixtures. In DL, SDSeries38 network exceeds 10 classical CNN and provides a generic architecture<span> enabling transfer application to other regression problem. DL application to regression is still in its infancy and there is no complete guide on how to develop specific CNN architectures for regression. Some gaps need to be filled: (1) Specially developed CNN architectures for regression are required; (2) The performances of direct transfer learning the classical CNN architectures from classification to regression are modest. A modular structure with typical function modules may provide an ideal solution; (3) Going deeper into the sequence of </span></span>convolution layers improves </span></span>predictive accuracy, but bears in mind to keep the number of layers below the threshold to avoid vanishing gradient.</span></span></p></div>","PeriodicalId":16361,"journal":{"name":"Journal of molecular graphics & modelling","volume":"111 ","pages":"Article 108083"},"PeriodicalIF":2.7000,"publicationDate":"2022-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of molecular graphics & modelling","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1093326321002540","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 3
Abstract
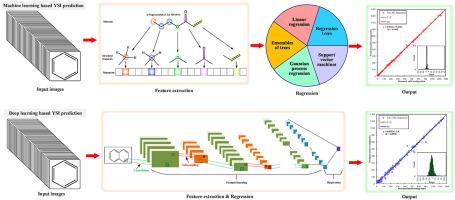
Soot formation models become increasingly important in advanced renewable fuels formulation for soot reduction benefit. This work evaluates performance of machine learning (ML) and deep learning (DL) to predict yield sooting index (YSI) from chemical structure and proposes a tailor-made convolution neural network (CNN)-SDSeries38 for regression problem. In ML, a novel quantitative structure-property relationship (QSPR) is developed for feature extraction and the relationship between molecular structure and YSI is built by ML algorithm. In DL, SDSeries38 contains 9 feature learning modules, 1 regression module for automated feature learning and regression. It adopts standard series network architecture and modular structure, each feature learning module is a stack of convolution, batch normalization, activation, pooling layers. ML-QSPR model outperforms SDSeries38 in accuracy (RMSE = 7.563 vs 19.58), computational speed and the former applies to fuel mixtures. In DL, SDSeries38 network exceeds 10 classical CNN and provides a generic architecture enabling transfer application to other regression problem. DL application to regression is still in its infancy and there is no complete guide on how to develop specific CNN architectures for regression. Some gaps need to be filled: (1) Specially developed CNN architectures for regression are required; (2) The performances of direct transfer learning the classical CNN architectures from classification to regression are modest. A modular structure with typical function modules may provide an ideal solution; (3) Going deeper into the sequence of convolution layers improves predictive accuracy, but bears in mind to keep the number of layers below the threshold to avoid vanishing gradient.
在先进的可再生燃料配方中,烟尘形成模型对减少烟尘的效益越来越重要。本文评估了机器学习(ML)和深度学习(DL)从化学结构预测产率指数(YSI)的性能,并提出了一个定制的卷积神经网络(CNN)-SDSeries38来解决回归问题。在机器学习中,提出了一种新的定量结构-性质关系(QSPR)用于特征提取,并通过机器学习算法建立了分子结构与YSI之间的关系。在深度学习中,SDSeries38包含9个特征学习模块,1个回归模块用于自动特征学习和回归。它采用标准的串联网络体系结构和模块化结构,每个特征学习模块是由卷积、批归一化、激活、池化层叠加而成。ML-QSPR模型在精度(RMSE = 7.563 vs 19.58)、计算速度方面优于SDSeries38,前者适用于燃料混合物。在深度学习中,SDSeries38网络超过了10个经典CNN,提供了一个通用的架构,可以将应用转移到其他回归问题。深度学习在回归中的应用仍处于起步阶段,并且没有关于如何为回归开发特定CNN架构的完整指南。需要填补一些空白:(1)需要专门开发用于回归的CNN架构;(2)经典CNN体系结构从分类到回归的直接迁移学习性能一般。具有典型功能模块的模块化结构可以提供理想的解决方案;(3)深入卷积层序列可以提高预测精度,但要注意层数要低于阈值,避免梯度消失。
期刊介绍:
The Journal of Molecular Graphics and Modelling is devoted to the publication of papers on the uses of computers in theoretical investigations of molecular structure, function, interaction, and design. The scope of the journal includes all aspects of molecular modeling and computational chemistry, including, for instance, the study of molecular shape and properties, molecular simulations, protein and polymer engineering, drug design, materials design, structure-activity and structure-property relationships, database mining, and compound library design.
As a primary research journal, JMGM seeks to bring new knowledge to the attention of our readers. As such, submissions to the journal need to not only report results, but must draw conclusions and explore implications of the work presented. Authors are strongly encouraged to bear this in mind when preparing manuscripts. Routine applications of standard modelling approaches, providing only very limited new scientific insight, will not meet our criteria for publication. Reproducibility of reported calculations is an important issue. Wherever possible, we urge authors to enhance their papers with Supplementary Data, for example, in QSAR studies machine-readable versions of molecular datasets or in the development of new force-field parameters versions of the topology and force field parameter files. Routine applications of existing methods that do not lead to genuinely new insight will not be considered.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


