Christopher E Gomez, Marcelo O Sztainberg, Rachel E Trana
{"title":"Curating Cyberbullying Datasets: a Human-AI Collaborative Approach.","authors":"Christopher E Gomez, Marcelo O Sztainberg, Rachel E Trana","doi":"10.1007/s42380-021-00114-6","DOIUrl":null,"url":null,"abstract":"<p><p>Cyberbullying is the use of digital communication tools and spaces to inflict physical, mental, or emotional distress. This serious form of aggression is frequently targeted at, but not limited to, vulnerable populations. A common problem when creating machine learning models to identify cyberbullying is the availability of accurately annotated, reliable, relevant, and diverse datasets. Datasets intended to train models for cyberbullying detection are typically annotated by human participants, which can introduce the following issues: (1) annotator bias, (2) incorrect annotation due to language and cultural barriers, and (3) the inherent subjectivity of the task can naturally create multiple valid labels for a given comment. The result can be a potentially inadequate dataset with one or more of these overlapping issues. We propose two machine learning approaches to identify and filter unambiguous comments in a cyberbullying dataset of roughly 19,000 comments collected from YouTube that was initially annotated using Amazon Mechanical Turk (AMT). Using consensus filtering methods, comments were classified as unambiguous when an agreement occurred between the AMT workers' majority label and the unanimous algorithmic filtering label. Comments identified as unambiguous were extracted and used to curate new datasets. We then used an artificial neural network to test for performance on these datasets. Compared to the original dataset, the classifier exhibits a large improvement in performance on modified versions of the dataset and can yield insight into the type of data that is consistently classified as bullying or non-bullying. This annotation approach can be expanded from cyberbullying datasets onto any classification corpus that has a similar complexity in scope.</p>","PeriodicalId":73427,"journal":{"name":"International journal of bullying prevention : an official publication of the International Bullying Prevention Association","volume":" ","pages":"35-46"},"PeriodicalIF":0.0000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8691962/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of bullying prevention : an official publication of the International Bullying Prevention Association","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42380-021-00114-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/12/22 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
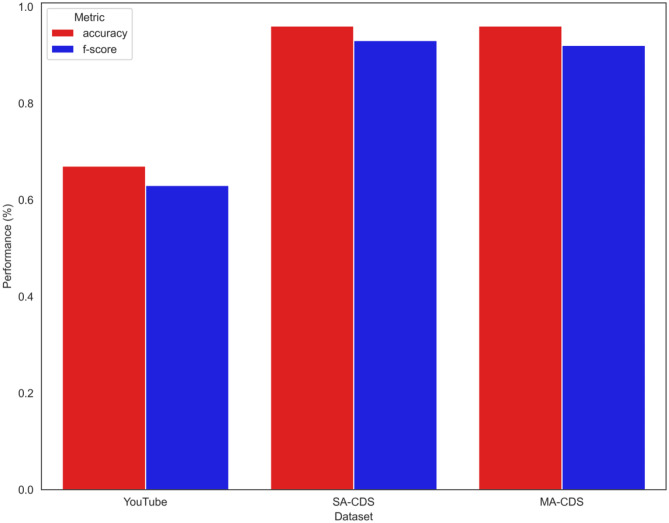
Cyberbullying is the use of digital communication tools and spaces to inflict physical, mental, or emotional distress. This serious form of aggression is frequently targeted at, but not limited to, vulnerable populations. A common problem when creating machine learning models to identify cyberbullying is the availability of accurately annotated, reliable, relevant, and diverse datasets. Datasets intended to train models for cyberbullying detection are typically annotated by human participants, which can introduce the following issues: (1) annotator bias, (2) incorrect annotation due to language and cultural barriers, and (3) the inherent subjectivity of the task can naturally create multiple valid labels for a given comment. The result can be a potentially inadequate dataset with one or more of these overlapping issues. We propose two machine learning approaches to identify and filter unambiguous comments in a cyberbullying dataset of roughly 19,000 comments collected from YouTube that was initially annotated using Amazon Mechanical Turk (AMT). Using consensus filtering methods, comments were classified as unambiguous when an agreement occurred between the AMT workers' majority label and the unanimous algorithmic filtering label. Comments identified as unambiguous were extracted and used to curate new datasets. We then used an artificial neural network to test for performance on these datasets. Compared to the original dataset, the classifier exhibits a large improvement in performance on modified versions of the dataset and can yield insight into the type of data that is consistently classified as bullying or non-bullying. This annotation approach can be expanded from cyberbullying datasets onto any classification corpus that has a similar complexity in scope.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


