{"title":"Examining data visualization pitfalls in scientific publications.","authors":"Vinh T Nguyen, Kwanghee Jung, Vibhuti Gupta","doi":"10.1186/s42492-021-00092-y","DOIUrl":null,"url":null,"abstract":"<p><p>Data visualization blends art and science to convey stories from data via graphical representations. Considering different problems, applications, requirements, and design goals, it is challenging to combine these two components at their full force. While the art component involves creating visually appealing and easily interpreted graphics for users, the science component requires accurate representations of a large amount of input data. With a lack of the science component, visualization cannot serve its role of creating correct representations of the actual data, thus leading to wrong perception, interpretation, and decision. It might be even worse if incorrect visual representations were intentionally produced to deceive the viewers. To address common pitfalls in graphical representations, this paper focuses on identifying and understanding the root causes of misinformation in graphical representations. We reviewed the misleading data visualization examples in the scientific publications collected from indexing databases and then projected them onto the fundamental units of visual communication such as color, shape, size, and spatial orientation. Moreover, a text mining technique was applied to extract practical insights from common visualization pitfalls. Cochran's Q test and McNemar's test were conducted to examine if there is any difference in the proportions of common errors among color, shape, size, and spatial orientation. The findings showed that the pie chart is the most misused graphical representation, and size is the most critical issue. It was also observed that there were statistically significant differences in the proportion of errors among color, shape, size, and spatial orientation.</p>","PeriodicalId":52384,"journal":{"name":"Visual Computing for Industry, Biomedicine, and Art","volume":"4 1","pages":"27"},"PeriodicalIF":6.0000,"publicationDate":"2021-10-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8556474/pdf/","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Visual Computing for Industry, Biomedicine, and Art","FirstCategoryId":"1093","ListUrlMain":"https://doi.org/10.1186/s42492-021-00092-y","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Arts and Humanities","Score":null,"Total":0}
引用次数: 5
Abstract
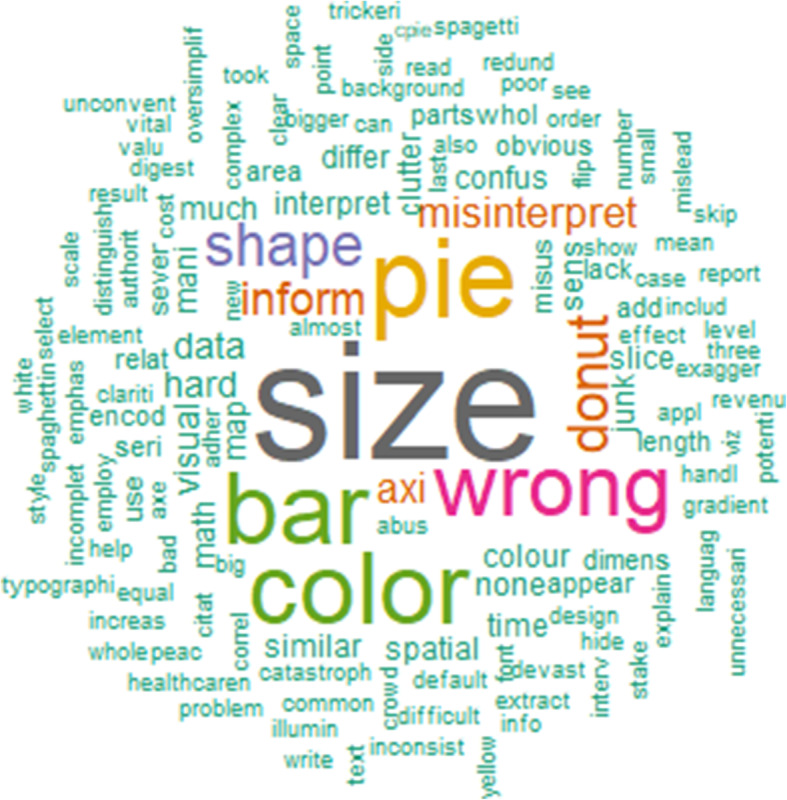
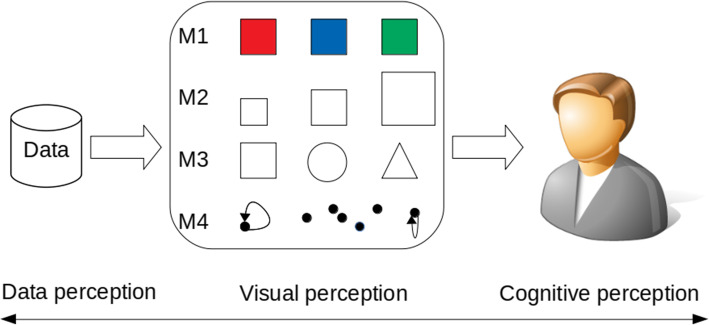
Data visualization blends art and science to convey stories from data via graphical representations. Considering different problems, applications, requirements, and design goals, it is challenging to combine these two components at their full force. While the art component involves creating visually appealing and easily interpreted graphics for users, the science component requires accurate representations of a large amount of input data. With a lack of the science component, visualization cannot serve its role of creating correct representations of the actual data, thus leading to wrong perception, interpretation, and decision. It might be even worse if incorrect visual representations were intentionally produced to deceive the viewers. To address common pitfalls in graphical representations, this paper focuses on identifying and understanding the root causes of misinformation in graphical representations. We reviewed the misleading data visualization examples in the scientific publications collected from indexing databases and then projected them onto the fundamental units of visual communication such as color, shape, size, and spatial orientation. Moreover, a text mining technique was applied to extract practical insights from common visualization pitfalls. Cochran's Q test and McNemar's test were conducted to examine if there is any difference in the proportions of common errors among color, shape, size, and spatial orientation. The findings showed that the pie chart is the most misused graphical representation, and size is the most critical issue. It was also observed that there were statistically significant differences in the proportion of errors among color, shape, size, and spatial orientation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


